Zoe
Member
So my college made a partnership with Microsoft and I got a DreamSpark Premium account, which means Visual Studio Ultimate 2013 for free")
So happy right now.
Amazingly my account still works with Dream Spark.
So my college made a partnership with Microsoft and I got a DreamSpark Premium account, which means Visual Studio Ultimate 2013 for free
So happy right now.
Amazingly my account still works with Dream Spark.
It sounds like Eclipse is pausing execution, probably because you're debugging and it hits an exception.Hello guys, I was wondering if any of you could help me out with this weird bug I keep getting:
I created a program which plots the popularity of names from 1900 to 2000 divided by decades, so there are 11 columns to display the statistics. I added 3 Jbuttons (Add[name], Delete[name], Clear[everything]) and a single JTextField where the user inputs the name to plot (if it exists in the database).
Everything works find except for when the user clicks the "Clear everything" button. If there's text inside the JTextField, the button does exactly what it's supposed to do: It clears the display screen leaving only the initial grid with the columns and the years at the bottom.
The problem arises when the JTextField is empty. If there's no text inside the field and the user clicks Delete, the program doesn't respond, it stays frozen and only throws some errors in Eclipse. The program doesn't crash; it just won't do anything unless there's at least one character inside the text field.
Any ideas as to what could be causing this problem? Would it be necessary to post some code for you to try to figure out what could be going on? Thanks in advance!
It sounds like Eclipse is pausing execution, probably because you're debugging and it hits an exception.
Well, my initial point was that:Why not? The theory is that the sooner you catch a bug, the cheaper it is to fix. Catching the mistake before it's made is a lot more efficient than catching it after days of development and causing more days to rework it.
int accumulate = 0;
int lmt = arr_sz - 4;
for (i = 0; i < lmt; j += 5)
{
accumulate += arr[i] + arr[i+1] + arr[i+2] + arr[i+3] + arr[i+4];
}
accumulate += last few elements not iterated through in the loop;int accumulate = 0;
int lmt = 10,000 - 4;
for (i = 0; i < lmt; i += 5)
{
accum1 += arr[i];
accum2 += arr[i + 1];
accum3 += arr[i + 2];
accum4 += arr[i + 3];
accum5 += arr[i + 4];
}
accumulate5 += last few elements not iterated through in the loop;
accumulate = accum1 + accum2 + accum3 + accum4 + accum5;accumulate += arr[i] + arr[i+1] + arr[i+2] + arr[i+3] +... ...+arr[9,999];That was the first thing I thought of, but then you lose all the delimiters in s1.
So a colleague is using VS13 and is seeing errors like this.
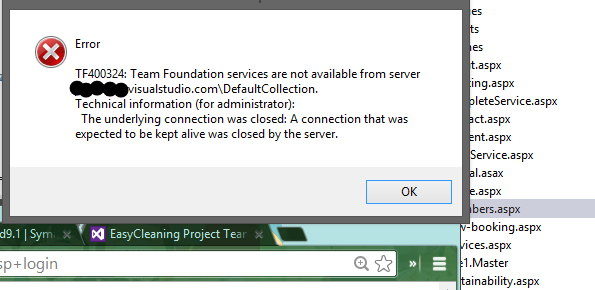
Whats that mean exactly? I'm a newb when it comes to VS.
I'm using Visual Studio Professional 2013 right now. What am I missing out on?
Nothing.
Are you guys using source control in TFS?
What language and compiler are you using and what compiler options?I'm trying to make a simple loop as efficient as possible. The loop adds up the sum of all elements of an int array. ~10 k elements in the array.
Loop unrolling gets me about a 2.5x speed increase. Example:
Code:Code
I have no idea why the 2nd technique of parallelism giving greater efficiency, as it did in my text. I'm guessing it's worth mentioning that the array size is not 10,000 exactly, but a prime number close to that amount. I'm guessing a prime number was chosen for a reason, but I cannot figure out why...or what I'm doing wrong. I need to get the fastest algorithm I can, without getting rid of the for loop. If someone can explain the behavior I'm seeing, and or give some techniques for possible further speed increases, that would be grand. Thanks.
What language and compiler are you using and what compiler options?
Why is python 2.7 still the standard. Seems to me turnover with Java and C++ to the newer versions is fairly common when new projects are started.
Although Python 3 has a lot of good stuff, I haven't ported my code to it because the interpreter has major incompatiblities and isn't installed by default in enough places yet. A lot of Linux distros are getting there but OS X still only comes with Python 2.7 last I checked. So since I don't want to inconvenience users by making them perform a separate Python install, I've stuck with 2.7.Why is python 2.7 still the standard. Seems to me turnover with Java and C++ to the newer versions is fairly common when new projects are started.
Why is python 2.7 still the standard. Seems to me turnover with Java and C++ to the newer versions is fairly common when new projects are started.
select * from table where value > 2.5C. Visual studio 2013. Optimization turned off, not sure what some of the other options do, but I think everything is just default.What language and compiler are you using and what compiler options?
I think this to do with low precision on floats, I use decimal as my datatype.SQL Question: Why does (hopefully I remembered correctly):
Code:select * from table where value > 2.5
also shows entries where the value (FLOAT btw.) is exactly 2.5? If I use INT it works like "it should".
I think this to do with low precision on floats, I use decimal as my datatype.
select * from table where value > 4.9select * from table where value > 4.91On mobile so I can't easily quote, the second to last paragraph of the this should explain the issue better than I can.Thank you for the information. Really strange behavior (in my eyes). I tried now a few combinations:
value1 = 4.9
value2 = 4.91
value3 = 5.1
Code:select * from table where value > 4.9
shows: value1, value2, value3
Code:select * from table where value > 4.91
shows: value3
Thanks that explains it.On mobile so I can't easily quote, the second to last paragraph of the this should explain the issue better than I can.
http://msdn.microsoft.com/en-us/library/ms187912(v=sql.105).aspx
C. Visual studio 2013. Optimization turned off, not sure what some of the other options do, but I think everything is just default.
But as far as answering "why not pair program?" assuming a team of experienced developers:
2) we get twice as much work done per unit of time. This is kind of a big deal
In my job I've done three new projects all of which were Python 3.3 (and then 3.4) based in the last six months. We also migrated a couple of older 2.6-based projects last week.Why is python 2.7 still the standard. Seems to me turnover with Java and C++ to the newer versions is fairly common when new projects are started.
In my job I've done three new projects all of which were Python 3.3 (and then 3.4) based in the last six months. We also migrated a couple of older 2.6-based projects last week.
Ah, okay. So, if you turn optimization on, hand-optimizing a loop like that (with unrolling and whatever) will do nothing, or at least nothing statistically significant. The optimizer will unroll loops for you, it will use vector instructions (SSE, AVX and all that) and there are also compilers that will automatically parallelize a section of code for you if you annotate it (OpenMP). You can be smarter than the compiler, but that's generally a lot of work and involves a lot of knowledge of the architecture you're coding on and also the assembly. I've tried making a 3D vector class in C++ that uses compiler intrinsics for addition/subtraction, dot product and the like, but all my attempts were at best as fast as the compiler's optimized version of normal, vanilla C++ code.
Unfortunately I can't use compiler optimizations. I think parallelism (the 2nd example) maybe requires an optimizing compiler to function as it should. With no compiler optimization I think the 2nd example is running slower than the first because there is no parallelism going on, yet there are a bunch of extra variables it has to access and deal with.
If this is the case, and my understanding is correct, then my 3rd example would make sense (completely removing the loop and explicitly doing 10000 adds). The only thing making any of the code samples run faster, as far as I can tell, is the fact that there are fewer jump instructions in the assembly code when I add more than one element into "accumulator" inside of the loop. If I add 5 elements in the loop before it jumps again, this cuts jump instructions down by 5 (vs only adding 1 element into accumulator per loop iteration).
By getting rid of the loop and having 10,000 explicit adds (which takes up an insane number of lines of code for something so simple), I completely get rid of all jump instructions. I guess the fastest code possible while keeping the for loop would be to do 2 loop iterations, and do 5000 adds in each iteration. Somehow I doubt this would be acceptable to my teacher, or what she is looking for.
I need to find a way to make the code more efficient that doesn't involve lowering the number of jump instructions or getting into the assembly code. I'm confused.
Yeah, that does make sense. Jump instructions means that a misprediction might happen, which leads to pipeline stalls. However, with a loop as simple as that and with branch predictors being as good as they are today, I can't imagine it would be a big difference. Do you have any information about the data stored in the array? Also, I think it might help if you go through the data once (before the real loop) to warm up the caches. This is pretty much the extent of my knowledge with low-level stuff, sadly.
Unfortunately I can't use compiler optimizations. I think parallelism (the 2nd example) maybe requires an optimizing compiler to function as it should. With no compiler optimization I think the 2nd example is running slower than the first because there is no parallelism going on, yet there are a bunch of extra variables it has to access and deal with.
If this is the case, and my understanding is correct, then my 3rd example would make sense (completely removing the loop and explicitly doing 10000 adds). The only thing making any of the code samples run faster, as far as I can tell, is the fact that there are fewer jump instructions in the assembly code when I add more than one element into "accumulator" inside of the loop. If I add 5 elements in the loop before it jumps again, this cuts jump instructions down by 5 (vs only adding 1 element into accumulator per loop iteration).
By getting rid of the loop and having 10,000 explicit adds (which takes up an insane number of lines of code for something so simple), I completely get rid of all jump instructions. I guess the fastest code possible while keeping the for loop would be to do 2 loop iterations, and do 5000 adds in each iteration. Somehow I doubt this would be acceptable to my teacher, or what she is looking for.
I need to find a way to make the code more efficient that doesn't involve lowering the number of jump instructions or getting into the assembly code. I'm confused.
The issue may have to do with the performance of the hardware prefetcher. Instead of using 10K array elements, try adding the first 1K elements ten times and see how that impacts the speed-up. As close to the edge said, you should also try to read the values prior to starting the benchmarking to prime the caches.
You can also take a look at the hardware performance counters and look at the cache miss rates and IPC.
I didn't catch whether you looked at the assembly code being generated by your compiler, but if not, that should probably be the first step. Calculate the actual number of instructions for each implementation. If one implementation is out-performing another, it is either due to fewer instructions or higher IPC (or both), and figuring out which is the first step to understanding the performance difference.
Lastly, make sure the OS is not interfering. Set the process priorities to real-time and disable any turbo modes/DVFS. Try to limit any other processes from running in the background.
A lot of that is over my head, this is my 3rd comp sci class, lol. I'll look at the assembly and see what I can understand of it. I'll look up what IPC is and/or how to access the hardware performance counter. We only learned the bare basics of assembly and she said she doesn't expect us to fully understand it or how to write good assembly code. But I will definitely look into those things.
As far as priming the caches, there's an outer loop that runs through the loop I gave several hundred thousand times. Wouldn't this outer loop prime the registers on the first run-through, or am I missing something?
My book also said that something called SIMD code is very efficient but never went into detail about how to use/implement it.
I haven't read books on how pair programming works, but I have experienced it: with extremely talented experienced developers, not-very talented developers, and with rookie developers.Assuming that these experiences developers have never read The Mythical Man Month, and that pair programming has zero productivity benefit, yes.
I can think of plenty of times during development on a number of projects where a lot of development time could have been saved if I'd been able to stop colleagues heading off down the wrong path or vice versa. I've never used pair programming in anger, and have been against it in the past for similar reasons to you, but I'm growing to think it could have some benefits even (or especially) in groups of skilled developers.
The less talented ones? To be blunt again, those are the people you fire.
Yes, unless there's some dependency that's unlikely to be ported soon (and the popular stuff has been by now) then you'd be best off using 3+ since it is the future of Python.I did pose the original question because I want to pick up python. For a long time I was told to learn 2.7, and most resources are still geared towards that. The core surely isn't too different, but would you say it's just best to start with 3.x going forward from now?
I haven't read books on how pair programming works, but I have experienced it: with extremely talented experienced developers, not-very talented developers, and with rookie developers.

The Mythical Man Month isn't about pair programming; it's about the misconception that two developers are twice as productive as one developer, and the idea that adding more manpower to a late project makes it later.
The Mythical Man Month isn't about pair programming; it's about the misconception that two developers working in parallel are twice as productive as one developer, and the idea that adding more manpower to a late project makes it later.
I think I'm the only one here who doesn't like pair programming. Every singe time I had to do pair programming I spent more time trying to explain to the other person why I was doing that than actually programming. I've worked two similar problems, and the one with pair programming took me three days to finish while the other one I finished it in one night.
I think I'm the only one here who doesn't like pair programming. Every singe time I had to do pair programming I spent more time trying to explain to the other person why I was doing that than actually programming. I've worked two similar problems, and the one with pair programming took me three days to finish while the other one I finished it in one night.
1) twice is a little strong for an average (since it's arguably the upper bound), but > 50% more productive apart is enough to be worth it. When everyone knows what they're doing, the time lost hurts more than the trouble saved.The Mythical Man Month isn't about pair programming; it's about the misconception that two developers working in parallel are twice as productive as one developer, and the idea that adding more manpower to a late project makes it later.
I know this is a joke, but here's advice anyway: just keep trying to get better. As long as he/she's improving, firing a developer is stupidity. (or necessity, in the case of layoffs...)I sense a long string of firings in my future...
I did pose the original question because I want to pick up python. For a long time I was told to learn 2.7, and most resources are still geared towards that. The core surely isn't too different, but would you say it's just best to start with 3.x going forward from now?
I sense a long string of firings in my future...
1) twice is a little strong for an average (since it's arguably the upper bound), but > 50% more productive apart is enough to be worth it.
2) adding more manpower to a late project doesn't make it later... but you can't use nine women to get a baby in one month, either.
public enum BodyTypes { bodyPlain = 1, bodyHTML = 2 };
public void SendEmail(string To, string Subject, BodyTypes bodyType, string Body, bool DisplayBeforeSend, string Attachment)
{
Type olAppType = Type.GetTypeFromProgID("Outlook.Application");
object objOutlook = Activator.CreateInstance(olAppType);
var CreateItem_Param = new object[1] { 0 };
object objMail = objOutlook.GetType().InvokeMember("CreateItem", BindingFlags.InvokeMethod, null, objOutlook, CreateItem_Param);
var mailItemType = objMail.GetType();
mailItemType.InvokeMember("To", BindingFlags.SetProperty, null, objMail, new object[] { To });
mailItemType.InvokeMember("Subject", BindingFlags.SetProperty, null, objMail, new object[] { Subject });
mailItemType.InvokeMember("BodyFormat", BindingFlags.SetProperty, null, objMail, new object[] { bodyType });
if (bodyType == BodyTypes.bodyPlain)
{
mailItemType.InvokeMember("Body", BindingFlags.SetProperty, null, objMail, new object[] { Body });
}
else if (bodyType == BodyTypes.bodyHTML)
{
mailItemType.InvokeMember("HTMLBody", BindingFlags.SetProperty, null, objMail, new object[] { Body });
}
//object objMailAttachments = mailItemType.InvokeMember("Attachments", BindingFlags.GetProperty, null, objMail, null);
object objMailAttachments = mailItemType.InvokeMember("Attachments", BindingFlags.GetProperty, null, objMail, new object[] {});
objMailAttachments.GetType().InvokeMember("Add", BindingFlags.InvokeMethod, null, objMailAttachments, new object[] { Attachment, Type.Missing, Type.Missing, Type.Missing });
if (DisplayBeforeSend == true)
{
mailItemType.InvokeMember("Display", BindingFlags.InvokeMethod, null, objMail, null);
}
else
{
mailItemType.InvokeMember("Send", BindingFlags.InvokeMethod, null, objMail, null);
}
}objMailAttachments.GetType().InvokeMember("Add", BindingFlags.InvokeMethod, null, objMailAttachments, new object[] { Attachment, Type.Missing, Type.Missing, Type.Missing });