You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
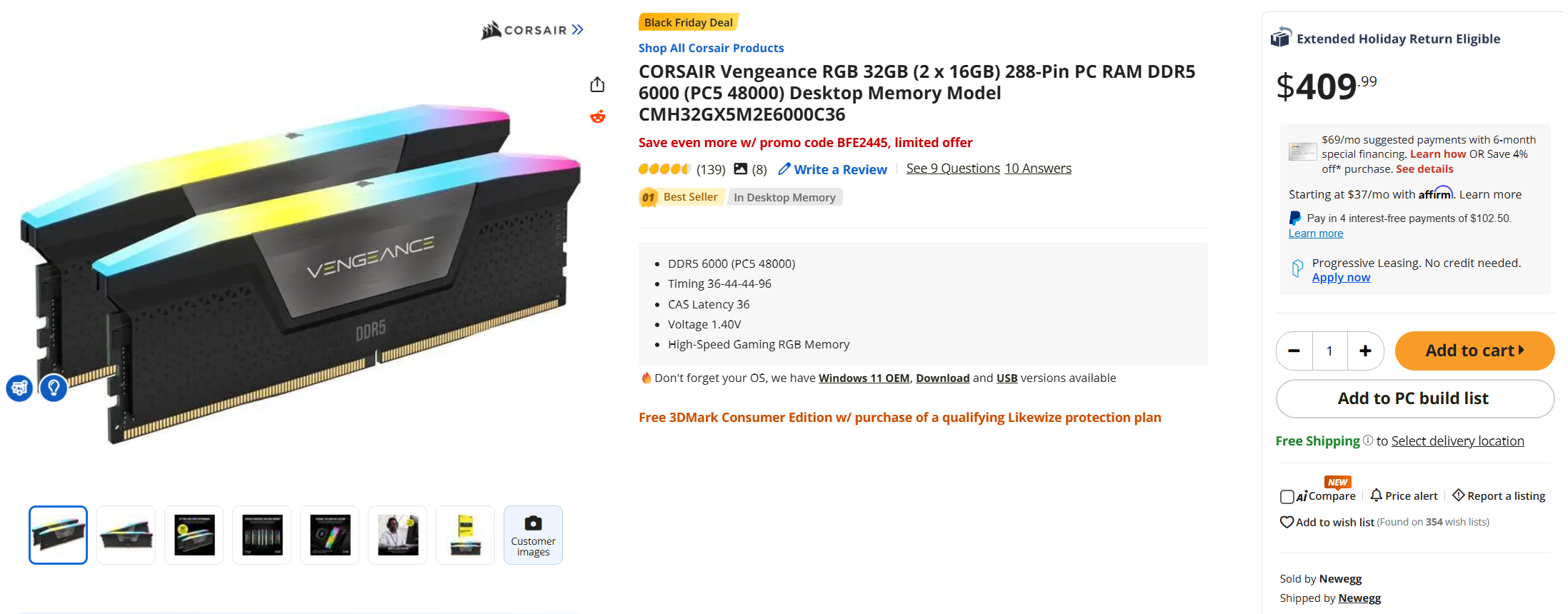
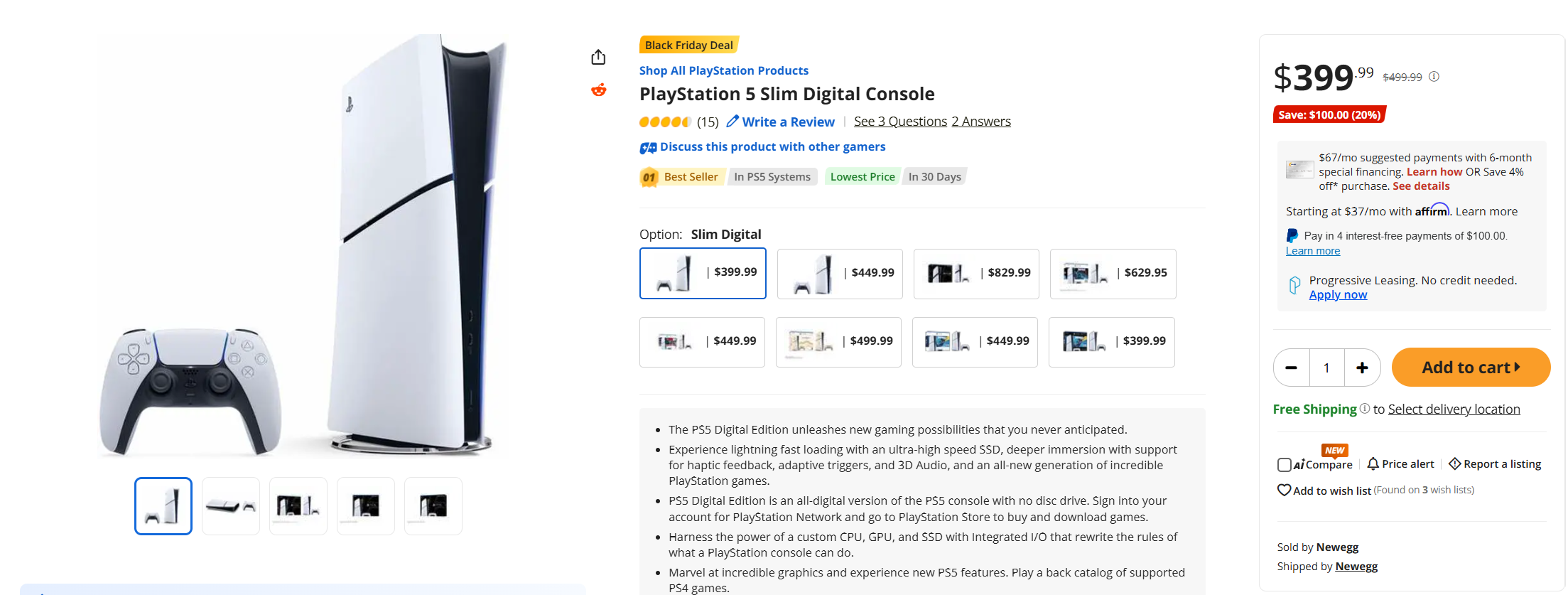
With Black Friday deals, some 32GB DDR5 RAM sticks are JUST a bit more expensive than a PS5 DE
- Thread starter LectureMaster
- Start date
- Drama Hardware
The_hunter
Gold Member

LectureMaster
Or is it just one of Adam's balls in my throat?

mckmas8808
Mckmaster uses MasterCard to buy Slave drives
This is insane!
Magic Carpet
Gold Member
Soon Industry will be buying PS5's to strip them of their guts to put in server blades.

Windom Earle
Member
I bought 64GB (KF560C30BBEK2) in January for half the price it is now, absolutely crazy.
LectureMaster
Or is it just one of Adam's balls in my throat?
You need to store the LLM on VRAM to efficiently run the models.AI demands so much RAM that AI boom skyrocketted the price. Im not much of a techy, but does AI really demand so much RAM?
Crayon
Member
Build now. Eat shit on the ram, save it back on some black friday deals. Get a machine built around a $500+ gpu now and you'll be able to use that for like 10 years because nobody's going to be able to afford to upgrade once the shit really hits the fan. The baseline is going to be stuck at PS5 for a long ass time. If you're on console only, maybe get that pro now.
If we have to halt somewhere for awhile, this is not a bad place to stop, though. I'm glad for that. Imagine getting stuck in the ps3 era when everything was choppy and raggedy.
If we have to halt somewhere for awhile, this is not a bad place to stop, though. I'm glad for that. Imagine getting stuck in the ps3 era when everything was choppy and raggedy.
MidGenRefresh
*Refreshes biennially
That is just a troll listing. You can still get 32gb at fairly low prices elsewhere
This. /thread
P:axMagellanic
Member
Everything is getting worse.
LectureMaster
Or is it just one of Adam's balls in my throat?
This is insane!

LectureMaster
Or is it just one of Adam's balls in my throat?
No. Sold and shipped by newegg, I specifically included this in screenshot.That is just a troll listing. You can still get 32gb at fairly low prices elsewhere
There are cheaper rams but not for this specific Corsair model.
Autistic_Pancake
Member
VRAM is required in enormous amounts. Even when you use a quantized version of AI (quantization reduces the precision of AI: for example, twice less size at the cost of 5 to 15% precision; models can be quantized even more aggressively, but the smaller AI is, the more its suffers from quantization - all the way down to becoming practically lobotomized), it is still ridiculous. Say, for example, you have a relatively dumb local AI model with 24 billion parameters. It can run on a single RTX 3090 (24GB VRAM) at 32k context length (it's about 20k characters). Some other model, let's say with 32 billion parameters, requires TWO 3090's to run at the same 32k context length (especially if the model is more complex and has more 'layers').AI demands so much RAM that AI boom skyrocketted the price. Im not much of a techy, but does AI really demand so much RAM?
Now, things like ChatGPT have trillions of parameters and they probably run at full precision (no quantization). Just imagine how much memory on the server do they gobble up, all things considered - millions of users around the world making requests at the same time, and such giants also have a huge context window size (going from 32k to 1m would increase VRAM consumption shockingly high).
As for the actual RAM (not VRAM), there are models that have "total" parameters and "active" parameters: like 100B total, 20B active (MoE architecture: Mixture-of-Experts, where a few 'experts' activate and use parts of 'total' knowledge somehow). The former could be loaded into RAM while the latter (together with context) loads into VRAM - and it gives a rather slow (compared to full VRAM) but nonetheless usable experience.
Using ONLY RAM is never a good way, unless it's some kind of unified memory (think of iMac devices, or whatever they're called now - those with M1 - M5 chips).
Point is, it's going to get only worse, since those assholes developing AI can't find a way to make their models more efficient. Everything they release now aims to 'know everything' and they feed more and more training data into their AI. All enthusiasts who want to use AI locally, beg the developers to give them smaller and faster models. That's also where all the fears about "AI everywhere (like in Windows)" come from: people know that only gigantic, huge AI is somewhat smart. And you can't put such a thing in every PC around the world, not now in 2025 at least - so, if Microsoft ends up shoving some kind of agentic garbage down the people's throats, it's going to be erroneous, non-reliable trash that would cause more harm than good. Probably smarter than local 24B - 32B models, but still shit, since there's just not enough hardware and electricity to saturate the whole world with 'good' AI.
Last edited:
yogaflame
Member
LLM? Hmm.You need to store the LLM on VRAM to efficiently run the models.
 I will research about AI later while at the same time working. Got to sleep. Thanks.
I will research about AI later while at the same time working. Got to sleep. Thanks.LectureMaster
Or is it just one of Adam's balls in my throat?
Large Language Model. Essentially need to store their whole algorithm (trillion of parameters) on the ram.LLM? Hmm.
Last edited:
yogaflame
Member
Very interesting what you wrote. I will research more about AI later. Got to sleep now and back to work later. Thanks.VRAM is required in enormous amounts. Even when you use a quantized version of AI (quantization reduces the precision of AI: twice less size at the cost of 5 to 15% precision), it is still ridiculous. Say, for example, you have a relatively dumb local AI model with 24 billion parameters. It can run on a single RTX 3090 (24GB VRAM) at 32k context length (it's about 20k characters). Some other model, let's say with 32 billion parameters, requires TWO 3090's to run at the same 32k context length (especially if the model is more complex and has more 'layers').
Now, things like ChatGPT have trillions of parameters and they probably run at full precision (no quantization). Just imagine how much memory on the server do they gobble up, all things considered - millions of users around the world making requests at the same time, and such giants also have a huge context window size (going from 32k to 1m would increase VRAM consumption shockingly high).
As for the actual RAM (not VRAM), there are models that have "total" parameters and "active" parameters: like 100B total, 20B active. The former could be loaded into RAM while the latter (together with context) loads into VRAM - and it gives a rather slow (compared to full VRAM) but nonetheless usable experience.
Using ONLY RAM is never a good way, unless it's some kind of unified memory (think of iMac devices, or whatever they're called now - those with M1 - M5 chips).
Point is, it's going to get only worse, since those assholes developing AI can't find a way to make their models more efficient. Everything they release now aims to 'know everything' and they feed more and more training data into their AI. All enthusiasts who want to use AI locally, beg the developers to give them smaller and faster models. That's also where all the fears about "AI everywhere (like in Windows)" come from: people know that only gigantic, huge AI is somewhat smart. And you can't put such a thing in every PC around the world, not now in 2025 at least - so, if Microsoft ends up shoving some kind of agentic garbage down the people's throats, it's going to be erroneous, non-reliable trash that would cause more harm than good. Probably smarter than local 24B - 32B models, but still shit, since there's just not enough hardware and electricity to saturate the whole world with 'good' AI.
Radical_3d
Member
Next gen is going to be so ass…
LectureMaster
Or is it just one of Adam's balls in my throat?
Good to know this. Makes sense cuz from what I've learned RAM+ CPU is way way inferior to VRAM+ GPU.As for the actual RAM (not VRAM), there are models that have "total" parameters and "active" parameters: like 100B total, 20B active. The former could be loaded into RAM while the latter (together with context) loads into VRAM - and it gives a rather slow (compared to full VRAM) but nonetheless usable experience.
Using ONLY RAM is never a good way, unless it's some kind of unified memory (think of iMac devices, or whatever they're called now - those with M1 - M5 chips).
Unknown Soldier
Member

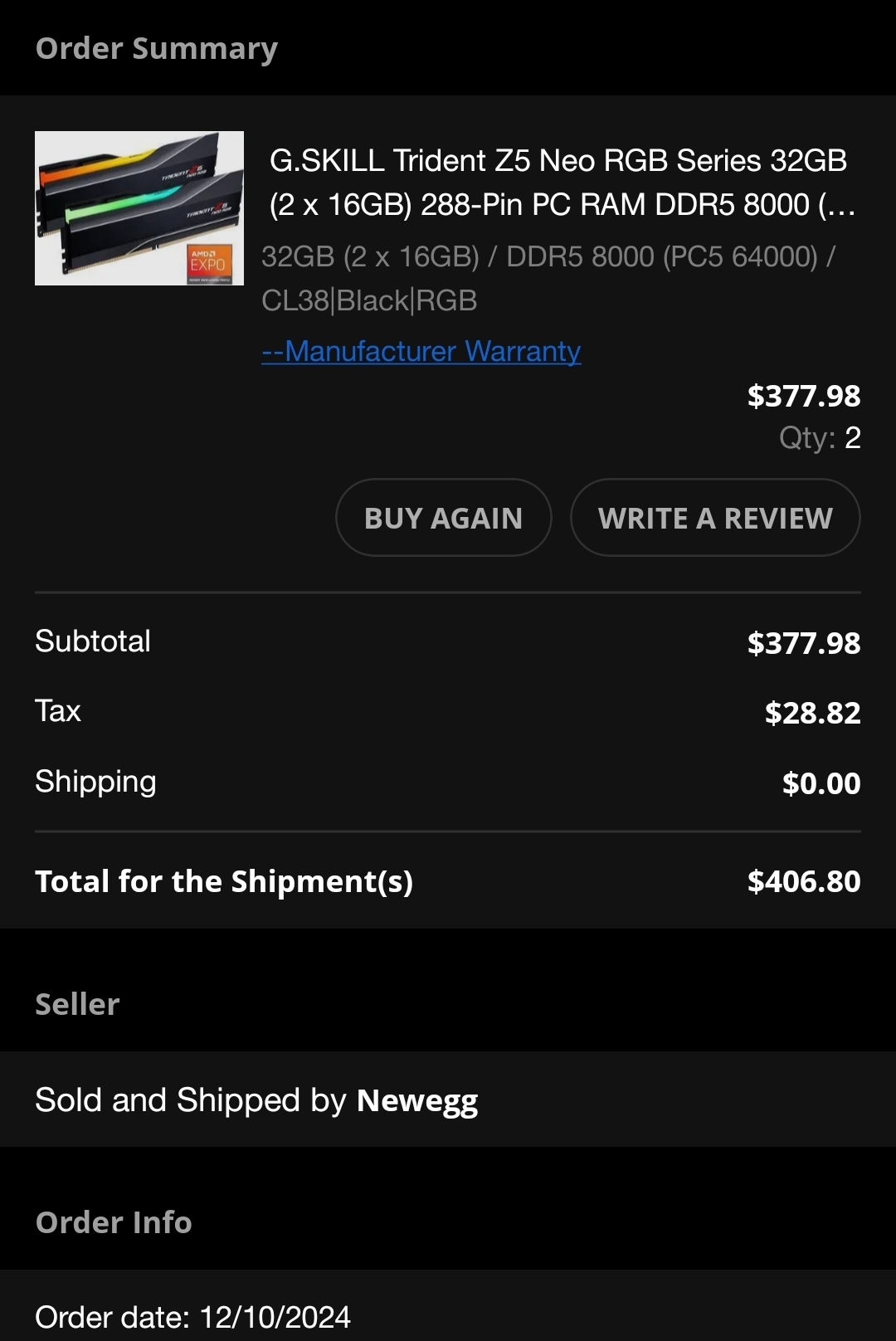
My man Newegg sold me these for Black Friday. I think picking the highest priced 32 GB DDR5 kit you can see and comparing it instead of the lowest priced one is a little disingenuous, even if the lowest priced one is still almost double what they cost just a few months ago
PumpkinBoy
Neo Member
Your obsession is becoming unhealthy.
kazuyamishima
Member
Last year the 32gb Corsair Vengeance 3200 was around $65 without sales.
Now the same stuff is around $120.
Now the same stuff is around $120.

So everything is being sucked up by AI servers, cloud servers whatever it is. Big corporations placing large orders and getting everything, first in line. The poor consumer who got you there is screwed, consoles probably get screwed eventually too.
Won't goverments think of the gamers for once? I can't wait to see the price of the Steambox now. This AI bubble can't burst soon enough.
Won't goverments think of the gamers for once? I can't wait to see the price of the Steambox now. This AI bubble can't burst soon enough.
RainblowDash
Gold Member
So glad I bought last year!
Jinzo Prime
Member
If you think these ram prices won't affect PS6 or PSN prices, I don't know what to tell you.
Mownoc
Member
They will but clearly it's not an imminent issue. If Sony thought it was going to be an issue for PS5 very soon they wouldn't be currently having aggressive discounts. They'd be trying to keep inventory so they don't have to manufacture as many PS5s with ludicrous prices.If you think these ram prices won't affect PS6 or PSN prices, I don't know what to tell you.
Companies are trying to ramp up production, a couple of years from now it probably won't be quite as big a problem as it will be over the next few months.
Last edited:
jm89
Member
They porbably will next year around spring time, but in the meantime they managed to stockpile some ram before the craziness to last them months.If you think these ram prices won't affect PS6 or PSN prices, I don't know what to tell you.
Last edited:

Unknown Soldier
Member
As I was saying in the other thread, if you're thinking of building or upgrading soon you need to accelerate your timeframe and do it nowUh... This price hyke is until next month or so, right?
Right?!
Prices aren't getting better in the short run on memory and they are about to get a lot worse on GPU and SSD soon
RafterXL
Member
I've been looking, because I'm getting the upgrade itch, and while that Op is a little misleading, it's not by much. The absolute cheapest stuff I would think about purchasing is around $250. Prices are stupid. Hell, the Corsair Vengeance I bought exactly 2 years ago on Amazon for $64 is now $156.
Still, it's only going to get worse and I've decided to upgrade this month, so does anyone know of a good way to sell a PC these days? All the usual places seem to suck now.
Still, it's only going to get worse and I've decided to upgrade this month, so does anyone know of a good way to sell a PC these days? All the usual places seem to suck now.
CentralScrutinizer
Member
I guess I will be riding my 32gb with a 4070s rig until the damn wheels fall off. I refuse to take part in purchasing hardware at these prices.
I'm not fucking upgrading.

I'm not fucking upgrading.
Last edited:
DonkeyPunchJr
World’s Biggest Weeb
If the AI bubble pops then our economy is pretty fucked. But it'll be fun to buy a bunch of dirt cheap computer parts.
El Hee-Ho
I bought a sex doll, but I keep it inflated 100% of the time and use it like a regular wife
You and me both man. It's not like modern gaming is giving me a lot of reasons to upgrade either.I guess I will be riding my 32gb with a 4070s rig until the damn wheels fall off