Buggy Loop
Gold Member
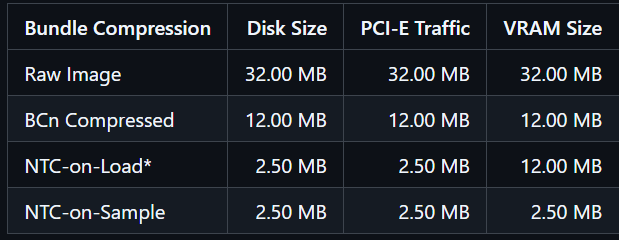
Google's turboquant is a compression algorithm for LLMs, it just changed the game. For some tasks it reduces memory usage by a factor of 6 while boosting performances by a factor of 8.

 research.google
research.google
The MLX creator already implemented it and had interesting results
Stock market it already reacted to it?

Could even the gaming GPUs benefit from this algorithm and save on VRAM requirements at every implementations of neural rendering?
Now the question comes for every such advancements that happens for over a hundred year, the Jevons Paradox

 en.wikipedia.org
en.wikipedia.org
Will the lower RAM requirement just mean that they'll scale these AI centers even more and basically cancel out the expectations of RAM availability? It's almost always like that. Their planning based on RAM scarcity is now relaxed, they can scale more.. Although energy is gonna be the immediate limit.
Fingers crossed it lowers prices

TurboQuant: Redefining AI efficiency with extreme compression
research.google
The MLX creator already implemented it and had interesting results
Stock market it already reacted to it?
Could even the gaming GPUs benefit from this algorithm and save on VRAM requirements at every implementations of neural rendering?
Now the question comes for every such advancements that happens for over a hundred year, the Jevons Paradox
Jevons paradox - Wikipedia
Will the lower RAM requirement just mean that they'll scale these AI centers even more and basically cancel out the expectations of RAM availability? It's almost always like that. Their planning based on RAM scarcity is now relaxed, they can scale more.. Although energy is gonna be the immediate limit.
Fingers crossed it lowers prices