1. So the answer to the question was, no because userland functions can't directly access the hardware and are still at the mercy of the kernel, which in linux and with opengl/vulkan wouldn't be an issue as the kernel is opensource and can be debugged with the graphics userland calls, but on windows it is closed source and you can't debug the kernel;s DX HAL that handles all GPU access, so if it haphazardly misses timings - eg with AMD drivers -which result in a cascade of latencies there is nothing anyone but Microsoft (or maybe nvidia) can do to eliminate those issues,
2. But again you side step the point about only needing resource for MSAA if it is the optimal solution - it isn't because newer TSR, FSR, DLSS and cognitive image enhancement yields higher PSNR measured over one or successive frames which MSAA can't do, so committing more bandwidth and silicon for what will be a deprecated ASIC feature isn't a win for Nvidia as a design choice.
I didn't say it didn't have the features, I was pointing to the efficiency with which UE5 (systems nanite/lumen) runs on the best of RDNA2 hardware designs (PS5) compared to Nvidia's RTX 20xxx or 30xx series and the nvidia hardware fails to scale with its numbers, because nanite runes lighter on PS5 than all other designs AFAIK. RDNA2 with RPM gets twice the micro polygons throughput of their native FLOP/s that compare to Nvidia cards without a 2x gain of RPM.
3. Nvidia cards have the full API for async, but as all the documentation mentions, using async on RTX is for light use because of excessive bandwidth use quickly causing negative performance gain on RTX with Async, and UE5 heavily exploits AMD's full bandwidth async that is used in the RDNA2/Series and PS5.
4. Yeah, that has been debunked here on GAF many times, and we are still awaiting comprehensive info about the PS5 GPU beyond the broad stroke numbers. We know that the lead architect Cerny choose the RT solution based on flexibility to lever more efficient RT algorithms like those he holds patents for, and believes it is an area that will undergo massive software advancement through the generation and that a less flexible set of core accelerators competing for CU memory bandwidth as in the RTX solution won't serve the problem nearly as well at the PS5 performance tier.
In Cerny's Road to PS5 reveal he states the shading and RT work are done at the same time on the PS5 GPU, where you kick of a BVH accelerator query and continue shading until the result is returned, whether that is achieved via the superior Async on AMD GPUs or via some other unrevealed aspect specific to the PS5 RDNA2 GPU design that isn't clear, but async compute on AMD GPUs is to use the gaps in between the graphics shader work, so it isn't a resource the graphics shader can use anyway to take the resource away.
5. techpowerup has the pixelrate for the PS5 in its database too, go compare yourself.
I'm not talking about the API, but the asynchronous utilisation of the hardware at low latency high bandwidth use - as cutting edge game rendering imposes on the problem. async on Nvidia is consider lite because it can only be used sparingly or when doing deep processing with low bandwidth needs at high latency access from what I've read.
1. Your open-source argument that degrades Linux's memory protection and multi-user design is meaningless for the majority of the desktop Linux use cases.
Linux followed Unix's supervisor and userland apps model and MMU usage is mandatory for the mainstream Linux kernel.
Linux has its own design issues e.g.
(Linus Torvalds on why desktop Linux sucks).
For SteamOS, Valve's graphics API preference is DirectX API on top of Vulkan via Proton-DXVK.
SteamOS effectively killed native Linux games for cloned Windows Direct3D-based APIs. Gabe Newell was the project manager for Windows 1.x to 3.x and Windows 9x's DirectX's DirectDraw.
Proton-DXVK effectively stabilized Linux's userland APIs.
On PS4 and PS5, game programmers operate within the userland environment on a thin graphics API layer and Direct3D-like layer. 3rd party PS4/PS5 game programers don't have X86's Ring 0 (Kernel level) access.
AMD GCN and RDNA support hardware virtualization.
2. Facts: Radeon HD 3870 has the full MSAA hardware.
NVIDIA's DLSS is powered by fixed-function Tensor cores that are separate from shader-based CUDA cores.
For Ryzen 7040 APU, AMD added "Ryzen AI" based on Xilinx's XDNA architecture that includes Xilinx's FPGA fabric IP. Expect AMD's future SKUs to include XDNA architecture from Xilinx (part of AMD) e.g. AMD also teased that it will use the AI engine in future Epyc CPUs and future Zen 5 SKUs would include XDNA for desktop AMD Ryzens since all Ryzen 7000 series are APUs (Ref 1). AMD ported Zen 4, RDNA 3, and XDNA IP blocks into TSMC's 4 nm process node for the mobile Ryzen 7040 APU.
Ref 1.
https://www.msn.com/en-us/news/tech...er-ai-ambitions-in-cpu-gpu-roadmap/ar-AAYhYv6
It also teased the next-generation Zen 5 architecture that will arrive in 2024 with integrated AI, and machine learning optimizations along with enhanced performance and efficiency.
For AMD's AI-related silicon, AMD has multiple teams from CDNA's (WMMA, Wave Matrix Multiply-Accumulate hardware), Xilinx's XDNA architecture, and Zen 4's CPU AVX-512's VNNI extensions. AMD promised that it will unify previously disparate software stacks for CPUs, GPUs, and adaptive chips from Xilinx into one, with the goal of giving developers a single interface to program across different kinds of chips. The effort will be called the Unified AI Stack, and the first version will bring together AMD's ROCm software for GPU programming (GCN/RDNA/CDNA-WMMA), its CPU software (AVX/AVX2/AVX-512), and Xilinx's Vitis AI software.
Like dedicated MSAA hardware, dedicated AI and RT cores hardware are to reduce the workload on GPU's shader cores.
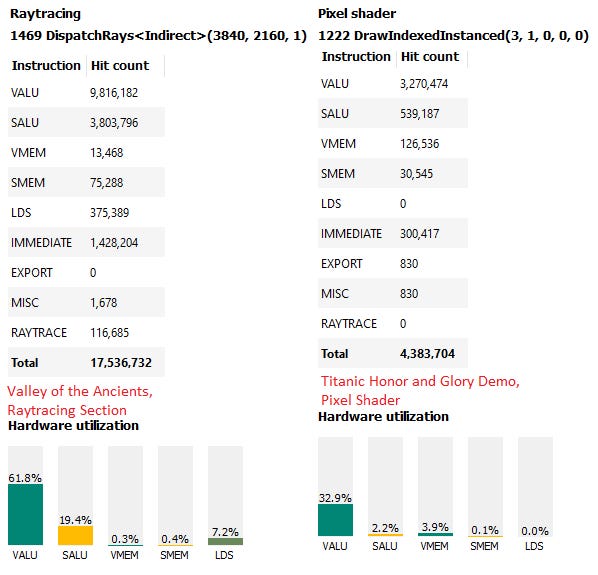
3. For the given generation, Async Compute extensive Doom Eternal shows Ampere RTX and ADA RTX performance leadership.
https://www.techpowerup.com/review/amd-radeon-rx-7900-xtx/15.html
Hint: Async Compute Shader path extensively uses
TMU read/write IO instead of ROPS read/write IO. RTX 4090 (
512 TMUs) 's superiority gap reflects its ~33% TMU superiority over RX 7900 XTX (
384 TMUs). Fully enabled AD102 (e.g. future RTX Geforce 4090 Ti) has
576 TMUs.
For GA102, 1 RT core: 4 TMU ratio.
For AD102, 1 RT core: 4 TMU ratio.
For NAVI 21, 1 RT core (missing transverse): 4 TMU ratio.
For NAVI 31, 1 RT core: 4 TMU ratio.
Spider-Man Remastered DX12 Raster
Like Doom Eternal, RTX 4090 (
512 TMUs) 's superiority gap reflects its ~33% TMU superiority over RX 7900 XTX (
384 TMUs)
Spider-Man Remastered DX12 DXR
Like Doom Eternal, RTX 4090 (112 RT cores, 512 TMUs) 's superiority gap reflects its ~33% RT superiority over RX 7900 XTX (96 RT cores, 384 TMUs).
From
https://www.kitguru.net/components/graphic-cards/dominic-moass/amd-rx-7900-xtx-review/all/1/
4. Prove it. PS5's RT results are within the RDNA 2 RT power rankings e.g.
Xbox Series X's Doom Eternal RT performance results are superior when compared to PS5's.
PS5's RT core is the same as any other RDNA 2 RT core i.e. missing the transverse feature. Prove Me Wrong!
PS5's RT cores did NOT deliver RDNA 3's RT core results.
One of the RDNA 2 RT optimizations (for XSX, PS5, and PC RDNA 2) is to keep the transverse dataset chunks to be small.
5.
Pure GPU pixel rate is useless without the memory bandwidth factor. Read GDC 2014 lecture on ROPS alternative via TMU path.







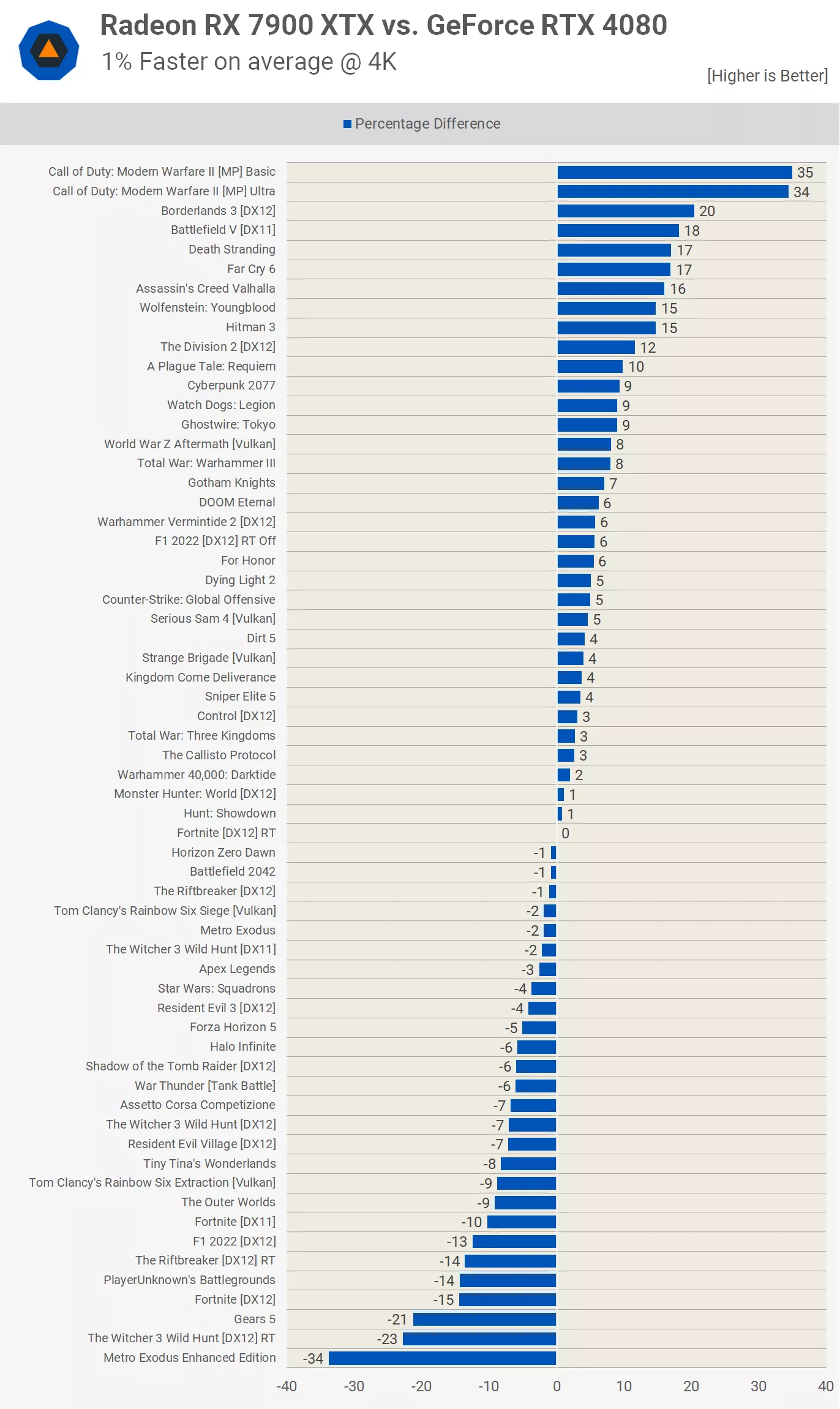





 For RDNA 3, welcome to NVIDIA's Ampere accelerated RT generation.
For RDNA 3, welcome to NVIDIA's Ampere accelerated RT generation.