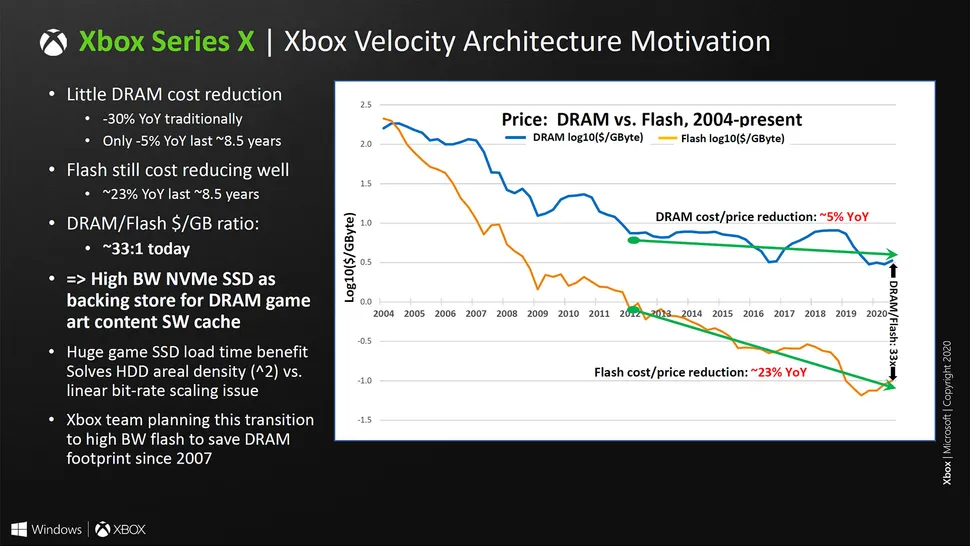
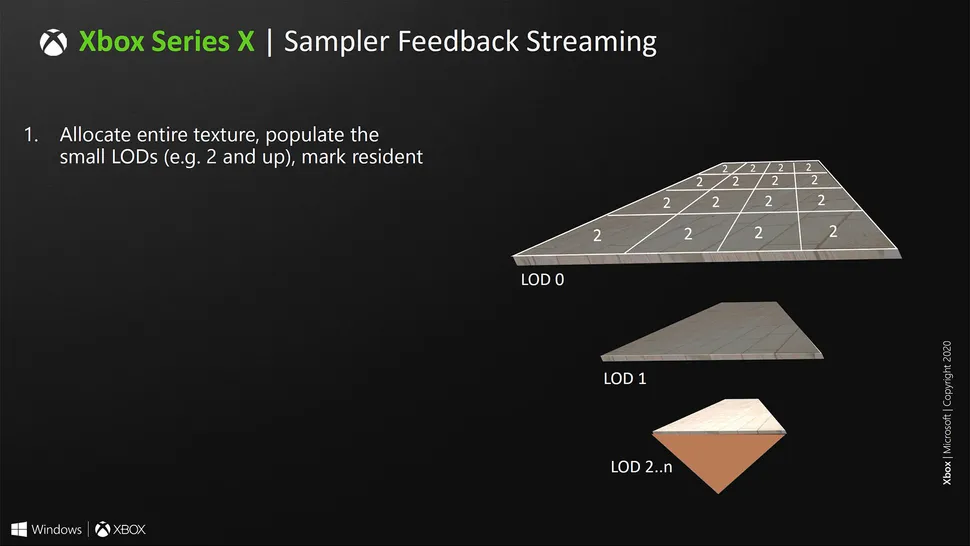
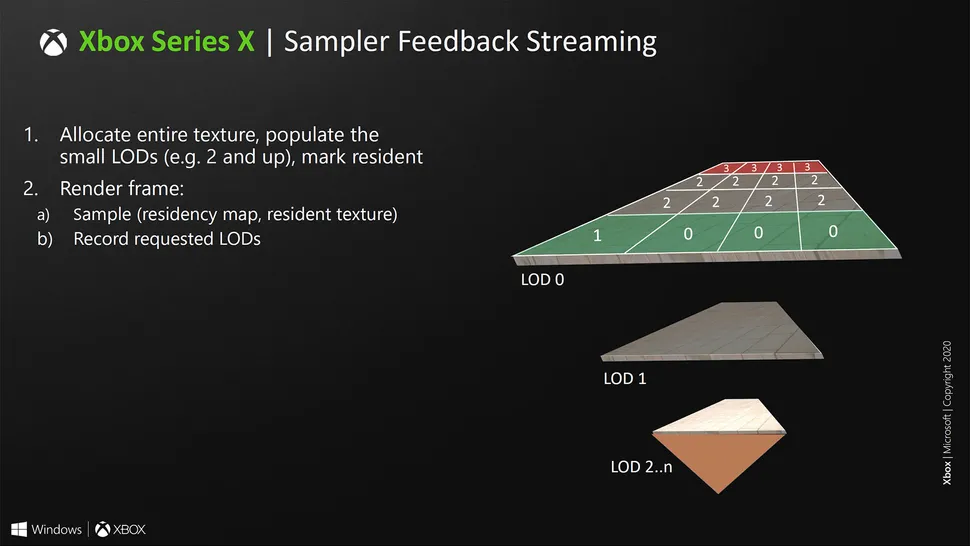
P
Panajev2001a
I don't think it's ever been suggested SF is "free"; free of an otherwise heightened silicon resource cost if implemented in a more generic fashion? Of course. But a feature that's just there to automate the process? No. That's part of the reason the GPU customization for texture/mip blending has been added, in case there is a miss and the higher-level mip isn't available in time.
That should suggest on it's own there is a "cost" in terms of programming efficiency but that really does fall back on the programmer of the software and might come with a slight learning curve to master. I'm assuming a dev can utilize ML to "train" a behavior for SFS logic and rely on the dedicated hardware to implement it as required, since it's tailored to the purpose.
No, I don't think Sony's just sticking to the same PRT features in PS4 and simply "port that over" to PS5; they've probably done some work on it. But, there's nothing guaranteeing they've taken the same approach as SFS and there's also no guarantee their approach will be as efficient, either. Assuming any sort of PRT "2.0" implementations in PS5 also leveraging async compute are present, you'd still have to consider how much async compute resources you'd need to push near the throughput of MS's efforts with SFS. And even in that case, SFS can probably be usable alongside more generic supplemental approaches that can leverage async compute of the Series GPU all the same.
I think the biggest question would be if any hypothetical PRT "2.0" on PS5 has the level of customization needed to warrant explicit mention by Sony (honestly I think if this were the case they would mention it in Road to PS5 wouldn't they?), and has been scaled up to a point of being usable for next-gen data streaming workloads. At the very least, whatever areas on this Sony are not focused on, devs can rely on roughly analogous approaches in engines like UE5, even if it means using a few more system resources to simulate it.
It'll probably be a mixture leaning with most weight to a more automated process, most likely. But, it will require
some effort: there's a reason there's blending hardware for the mips in case there's a miss on the higher-quality mip in time.
Devs probably need to get acquainted with it a bit but, since it's a (pretty massive) evolution from PRT in terms of the foundation, devs should be able to get easily familiar with it and can push utilization of it throughout the hardware's life cycle.