DemonCleaner
Member
It be here...
L0 cache 2 per dual cu each 16kb 32 way
L1 cache for each 5 dual cus 128kb 16 way
L2 4mB 16 way
This has 40 cus ( 4x10) ... most likely upgrade is to add one dual cu to each group = (4x12) 48 cus .. or add a whole extra group = (5x10) 50 cus ... or do both = (5x12) = 60
56 active seems likely
If you add a whole new group you will add more latency and wont be able to clock as high.
what you refer to as a "group" is called shader array in RDNA. i've drawn a navi 10 diagramm back in august to show what's what:
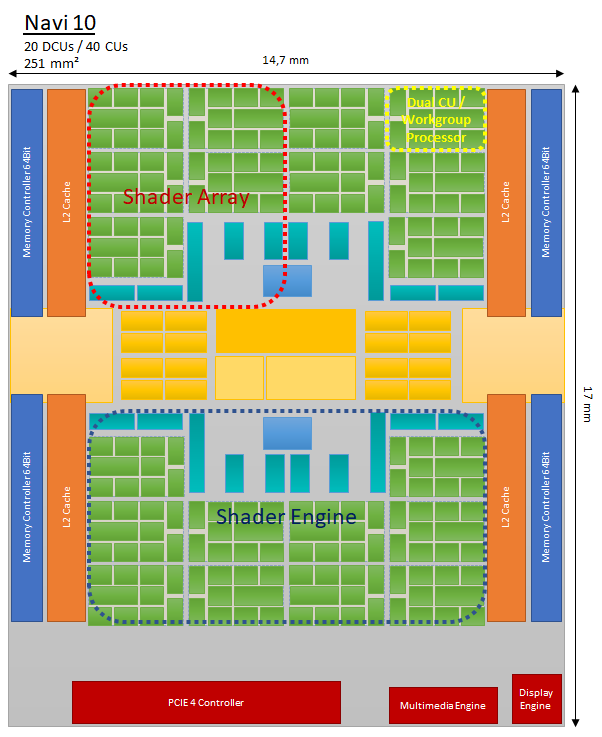
the problem with that
.. or add a whole extra group = (5x10) 50 cus ... or do both = (5x12) = 60
is, that each shader array shares parts of it's front end with another shader array to form a shader engine. so you had to add a whole new shader engine. while that would be nice, that die would become rather big at that point.
so in the gonzalo thread i speculated about adding four CUs per shader array, which would also make spacial sense. that would give 56CUs of wich you would likely have to dissable some for yield reasons:
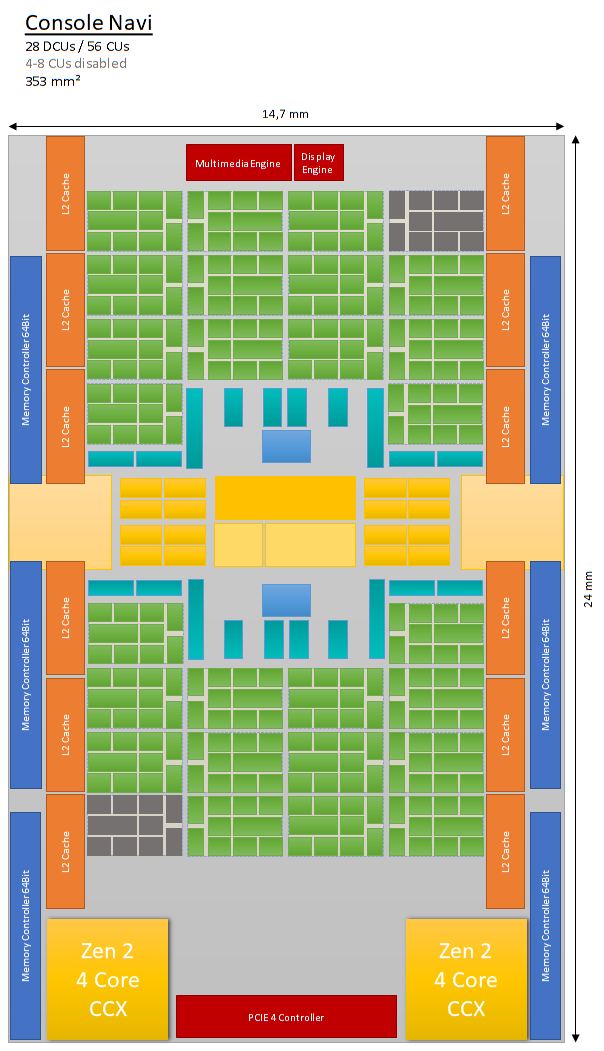
we don't know, how dCUs are disabled in RDNA. in GCN you had to disable one CU per shader array to maintain load symmetry. it not clear if this is still necessary with RDNA.
so there are lot of options for such a layout. and going by navi 14 there are other spacial layout options as well that could make sense.
If you add a whole new group you will add more latency and wont be able to clock as high.
i don't think that this is necessarily true. there's no clock speed disadvantage between navi 10 and 14. the challenge would be to keep the additional CUs fed. but thats more a front end / logic issue as long as you have sufficient bus bandwidth.
the point why larger dies often have lower clocks is, because the probability of less than stellar silicon is higher and even more than that heat density is becoming critical in such dies.




 You can clearly see he's stalking the Gaf page from the screen shot lol.
You can clearly see he's stalking the Gaf page from the screen shot lol.


 bcus you know there's only one side of fanboys. You'd be surprised what sides would really implode given past history.
bcus you know there's only one side of fanboys. You'd be surprised what sides would really implode given past history.


