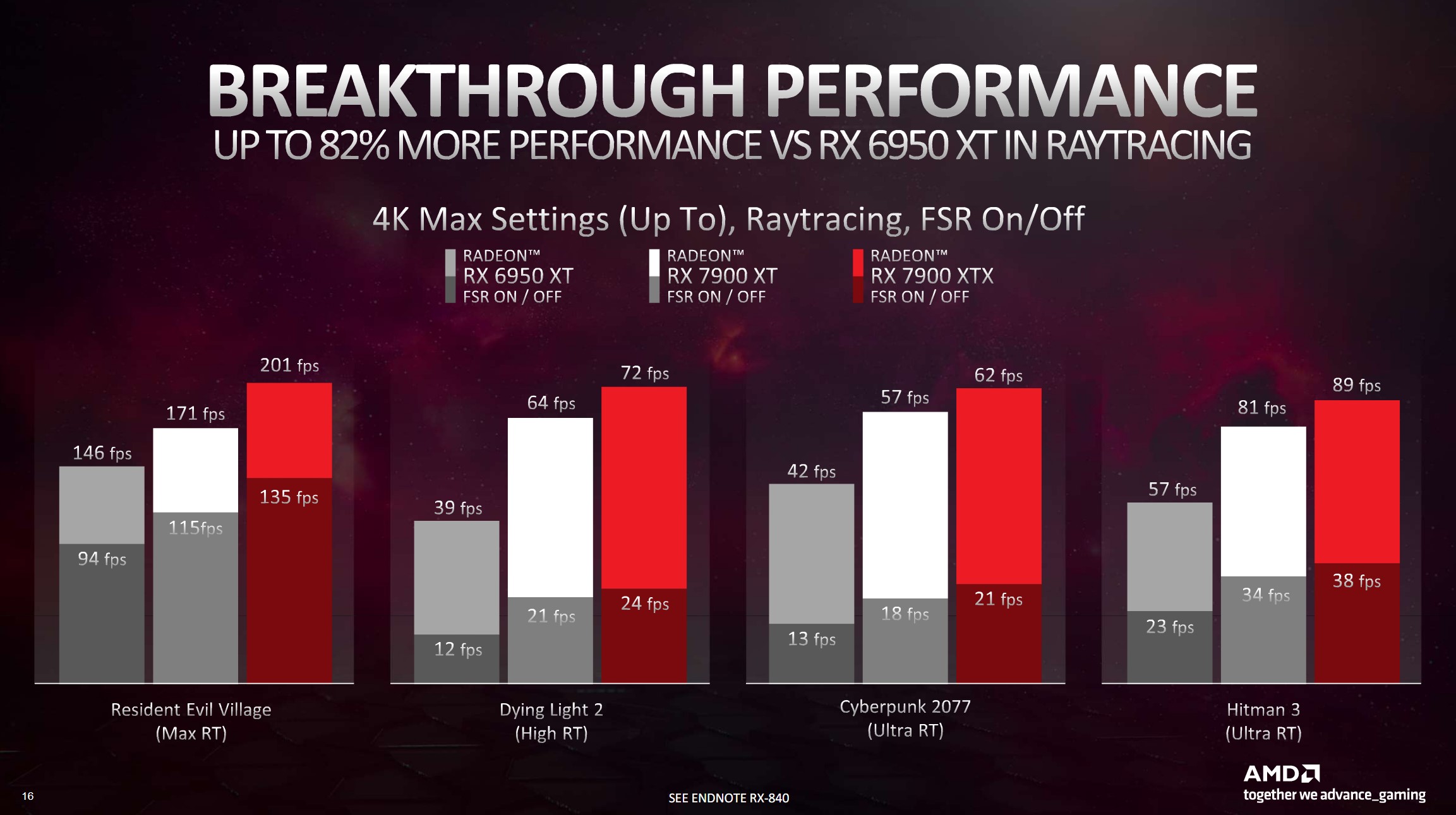
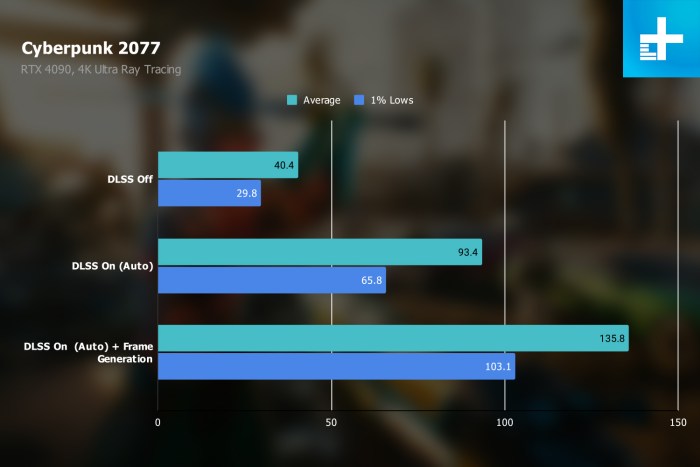
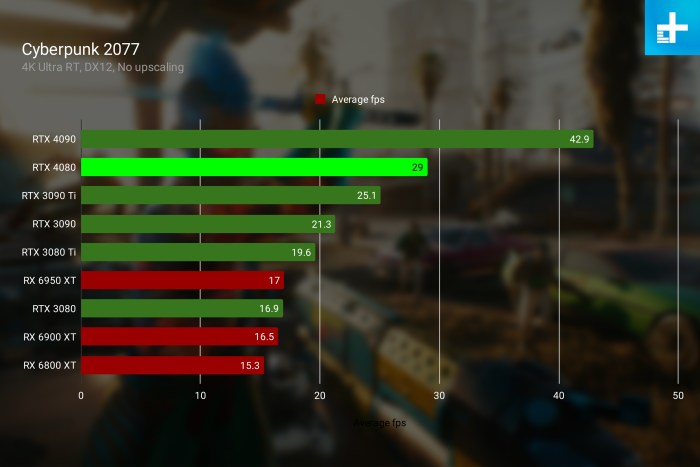
Now that people are bringing Intel into the equation, I was curious about the state of async compute on Intel and Nvidia, and in relation to your response to
 SlimySnake
SlimySnake
- which in my opinion is nonsense to suggest UE5 nanite and lumen are broken or incomplete because Nvidia hardware is struggling to get gains - it turns out Intel have backed different strategies from AMD/Nvidia, taking the Rapid Packed Maths arrangement of getting double flops when using half flops FP16 like AMD - that Nvidia hardware is deficient with, and on the Nvidia side they've gone with dedicated hardware based AI super scaling, and dedicated hardware RT accelerators, which from reading means they have the same deficient async compute "lite" - as it has been dubbed - as Nvidia because the async copy engine used for copying/compute are just re-tasked RT cores, so the scheduling parallel work can cripple performance if used as liberally as the AMD async compute - that is designed for heavy async use with dedicated ACEs - and in turn Nvidia and Intel's async costs in lost RT processing too.
Why this is relevant to UE5 nanite and lumen performance is because from the technical info we've had from Epic about the algorithms and the data, it seems that both algorithms were designed to be processing centric, rather than the traditional data centric, so both algorithms just chunk through the data - as though it is all conceptually the same generic data - in very optimised graphics/compute shaders, still able to exploit the likes of mesh shaders, but without the inefficiency of constant shader and resource binding changes. If UE5 is performance constrained at 4k-1080p on high-end Nvidia cards, then it sounds like the rendering is hitting a hard geometry processing limit on the card and the lack of proper async capability is stopping them going beyond that limit with async compute, and is unfortunately hitting a graphics + compute utilisation limit on the Nvidia cards lower down the utilisation limit because Nvidia's solution being better designed for data centric rendering has handicapped it more for generic processing centric rendering like UE5, would be my take.
Just adding the Intel Arc A780's balance of stats into the mix of cards me and
SlimySnake
were previously looking at - in comparison to these AMD 7900 - now IMO gives an inkling that Nvidia are all-in and possibly wrongly, and that the lack of proper async, the dependency on FP32 - with no option for 2x FP16, instead - and DLSS and RT hardware accelerators mean that if the performance flips to AMD, which I think it will heavily with the AMD 8000 series, Nvidia might have a harder way back than Intel, as Intel have already designed around the FP16 Rapid packed maths, at least and still have chosen a good balance between Half-Flops-rate, pixel-rate and texture-rate even if the poor power efficiency looks to be shared with Nvidia because of the dedicated AI super scaling hardware and dedicated RT cores.

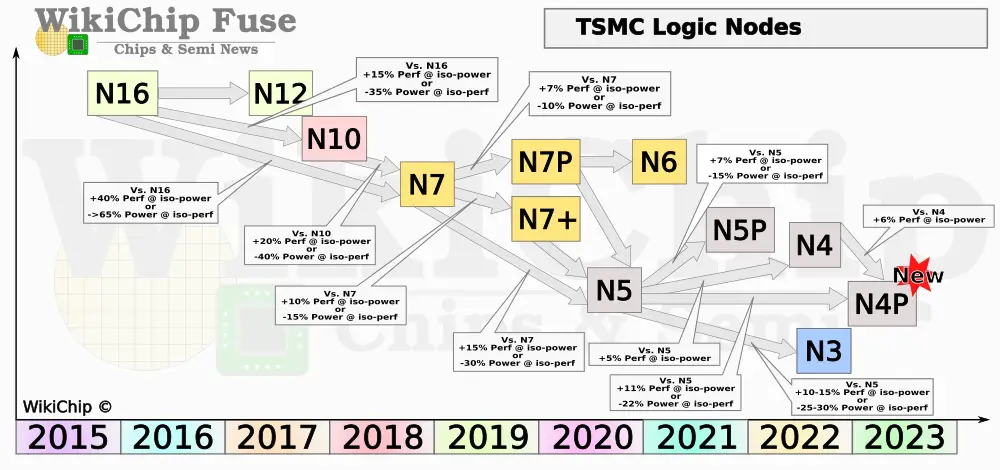


 ).
).