IbizaPocholo
NeoGAFs Kent Brockman
NVIDIA Audio2Face uses AI to generate lip synching and facial animation, showcased in two games
Generative AI is slowly but surely making its way into gaming, and NVIDIA's AI-powered Audio2Face is game changer for facial animation and localization.
 www.tweaktown.com
www.tweaktown.com
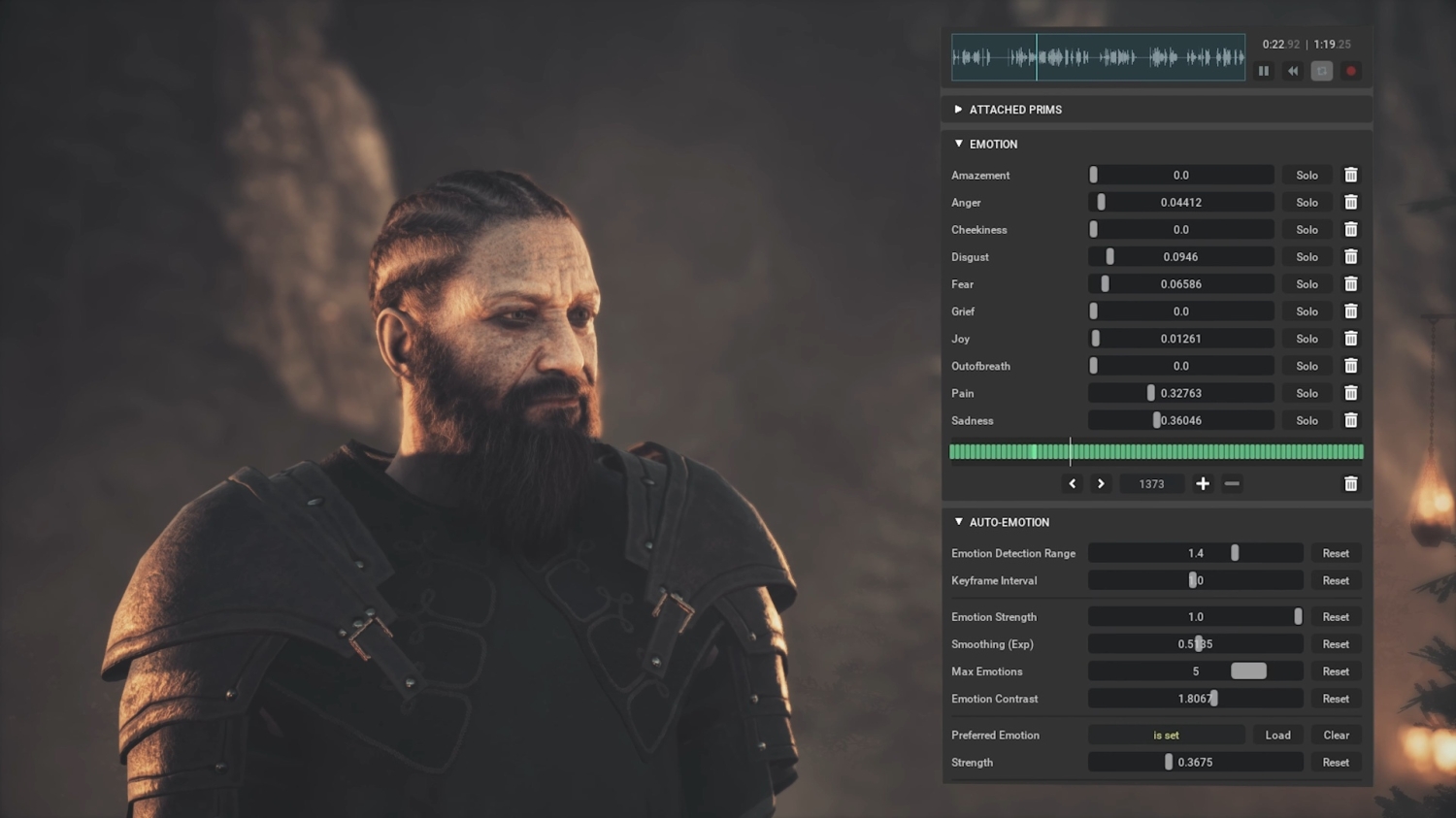
NVIDIA Audio2Face is a powerful generative AI tool that can create accurate and realistic lip-synching and facial animation based on audio input and character traits. Developers are already using it.
Facial animation involves communicating a character's emotion, which makes the tool invaluable because it can pair words with emotion to present a fully animated dramatic facial performance.
The first game featuring the tech is World of Jade Dynasty, a martial arts MMO from the Chinese studio Perfect World Games. With NVIDIA Audio2Face, the studio can generate accurate lip-synching and animation in Chinese and English. As an online title, NVIDIA Audio2Face will allow developers to add new voiced content with the same realistic animation.
The second game showcasing the tech is RealityArts Studio and Toplitz Productions' Unreal Engine 5-powered Unawake, a new action-adventure game launching later this year with DLSS 3 support. This video presents a dynamic look at NVIDIA Audio2Face in action, showcasing the various sliders covering various emotions.