I guess you overestimating the Ampere architecture, that also started to double flop counts, which resulted in about 5-10% extra performance (situation based). This chip is small an lower clocked and therefore doesn't outmatch series s GPU performance. Especially as it has really low bandwidth. Yes the series s GPU is quite small, but this is even smaller and slower.
?
I don't get it
Fafalada was talking about the rog ally PC handhelds compared to series S, or am I misunderstanding his post. Not Switch 2.
→ Now, Switch 2 will never beat series S. Not at those clocks. I don't know why this is coming back. It's groundhog day. This is the end of that story. Some rando on twitter saying GTA 6 is coming should not even get the attention.
Now again, the following is all compared to
PS4 / PS4 Pro. Modern consoles have the following features so its not an argument to think that switch 2 can suddenly catch up to consoles or something. I want to kill this argument because no, won't happen. But this is in response to "modern architecture won't bring anything" peoples.
The « double TFlops » being fake or something on ampere is taking the easy route. Games don't work like that like that, especially not modern ones. The extra cuda core is basically a pascal one, that does either FP32 or INT32 (and sub variants FP / INT of that)
Since Turing they introduced concurrent FP32 & INT32.
Ampere just did FP32 & FP32/INT32. Meaning that when the compute part is done they also flip to FP32 to finish tasks faster and have better occupancy.
PS4 and old GPUs don't have concurrency. New consoles do. So wanting to slice switch 2 teraflops in half is like trying to clock the whole pipeline on PS4 after it is done with compute
It's why the PS4 games coming to PC are shown as being heavily raster dependent over compute because devs were avoiding it like the plague. A raster heavy will still benefit from the 2nd cuda core in FP32, but where this architecture leverages the best is FP32 & INT32 concurrently.
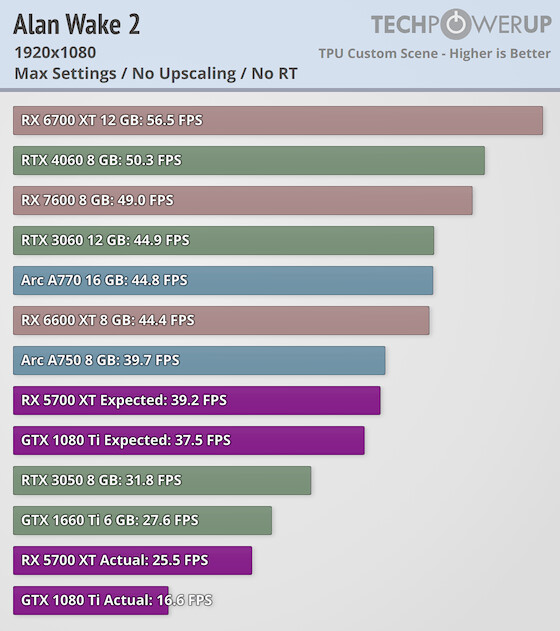
Games nowadays are leaning a lot more into compute. Cyberpunk 2077, Alan wake 2, UE5
Look how mesh shader which makes the pipeline compute-like flexes its muscles on Turing and beyond
Titan X has FP32 6.691 TFlops
5700 XT has FP32 a whooping 9.754 TFflops, "true" TFlops if you want to call it that
2060 Super has FP32 7.18 TFlops
They can all do mesh shaders, the difference is FP32/INT32 concurrency.
Look even a 1660Ti which is turing architecture but at 5.437 TFlops surpassing the 9.7 TFlops raster monster. They even included where these cards should have been expected to be in the chart but fall down the ladder. RDNA 2 is fine because of course the architecture changed to optimize for it.
Now
why use mesh shaders? There's already a lot of documentation on it but here's TLDR
- Serialized fixed function pipeline are limited by bandwidth and if you try to push more triangles than you can through that pipeline it doesn't scale.
- By going with full programmable it scales to all the cores you've got on the GPU.
- The pipeline is "compute-like" and Turing/Ampere loves that.
- You remove the bottleneck in the middle of your vertex shader and your pixel shader of traditional architectures, telling you no, this is the fixed rate of triangles I can output.
- The new method also optimizes vertex reuse, reduces the attribute fetches.
- Because they are reduced to tiny meshlets, they stay in cache, rather than fetching stuff from really far into main GPU memory or even worse the system memory.
- The geometry can work entirely in pipe. It's made much like Nanite, for big geometry with automatic culling and LODs. Procedural instancing for hair / vegetation / water which are geometry intensive.
Seems like a match made in heaven for a mobile platform where you do not want to fetch too much often from LPDDR5x memory and use the dual cuda cores to its full potential
Will
all devs use it to its full potential? Well no. Alan wake 2 as far as I know is the first using it. But that's usual for PC tech and crossgen has contaminated the jump for years.
Nvidia is making the switch 2 API. Do you not think that Mesh shaders is not heavily promoted in the devkit? Of course they will promote these methods to get more performance out of it, especially since its Nvidia's invention.
Even AMD recommends it, but we're still so stuck into years and years of PS4 crossgen, support is only just starting.
It
is the future
I'm not expecting From Software to understand it nor change for it for Switch 2, but the Switch 2 "impossible ports" will of course use this.
Then inherently Ampere also had a massive jump in occupancy and memory management compared to Turing
- Improvements in concurrent operations (concurrent raster/RT/ML, which Turing was not)
- Asynchronous barrier to keep execution units always near full occupancy
- Ampere global memory traffic for asynchronous memory copy and reducing memory traffic
- Also serves to hide data copy latency
Then Switch 2 supposedly from leaks that also DF has shared has backported Ada's gating, which helps with SM occupancy and power optimization. On top of having a file decompression engine.
Now how much % per above features, who the fuck knows really, especially since these architectures were stuck on bloated OS with bloated general drivers with CPU overhead all this time. But certainly not 0%.
It was designed to be a mobile chip and therefore also has all the flaws a mobile chip has against a desktop GPU.
No. Tegra is full Ampere SMs architecture. No cache cuts, no removal of tensor cores or RT cores per SM. It's Ampere. The Tegra die were huge. DLA was added for even more TOPs on these chipsets.
AMD APUs do cut a lot from their desktop GPUs. Removing infinity cache, and/or slapping Zen 4 bandwidth hungry cores with mobile memory is indeed a bad fucking mix. Steam deck being the more balanced of the PC handhelds imo. But the ROG ally series introduces a lot more limitations than their desktop counterpart.
Go back to the first cards that supported dlss. They were always limited in what dlss could do, because of the limited resources. E.g. framerate & resolution limitations (stricter the smaller the cards got). You need some reasonable processing performance to even start. And even slower than the rtx 3050... you really don't want to see the results...
Why wouldn't we want to see?
Now what DF has done is choke the 2050 which already chokes on 4GB Vram, by lowering the clockspeeds into regions that its not optimized for. They are trying to mimic docked mode Teraflops with handheld mode bandwidth because that 96GB/s is obliterated. It don't work like that. It's a cute experiment at the best they could get their hands on.
Rich says it clearly
"Now before we go on, let's be totally clear, here this is the closest approximation we can get for the T239 GPU, but more accurately what you're going to see is an ultra low-spec ampere GPU running at mega clock speeds
starved of memory bandwidth"
and without even going into 4GB of VRAM issues you would have for Plague tale requiem and Cyberpunk 2077. You can't even raise up internal res without overflowing it.
DLSS is not a free lunch, but that's with general models for PC and not considering DLA. But even without considering that, 2050 heavily downclocked still can have DLSS.
But i'm pretty sure Nvidia engineers did not go to make a custom T239 for a console and then in the concept phase decide that it should kneecap the biggest technological tech associated to them for the past 5 years, DLSS. DLSS for sure is coming in docked mode. Handheld would have much better efficient upscaling solutions with low power mode that you wouldn't see the difference on a 8" screen, and that's what Nintendo's upscaling patent seems to cover.









/https://fbi.cults3d.com/uploaders/14308641/illustration-file/1ac9891b-a42e-4991-9347-47cd6d9cf4e7/VID_20220303_142133_1.gif)