thought of the day on PS5 / navi / RDNA:
some weeks back when DF's richard did his next gen speculation video, we uniformely had the opion it's just a summary what we had speculated in this thread over the last half year. yet he noticed something that everyone else missed. transistor density on Navi10 did increase significantly over the last GCN installments. if we actually do the math it accounts to 63% over the last somewhat comparable polaris 10 die with 36CUs as i tried to show in the following chart.
*note that is total transistors on die divded by the CU count of a full (undisabled) die
so what are all those additinal transistors for? as we learned in the AMD presentation at E3 they "streamlined" the graphics pipeline. historically nvidia had had a longer (and therfore more die space intensive) pipeline which allowed them to clock relatively high compared to amd on the same node. now that alone can't have been the driving force behind amd's redesign as we barely - if at all - see better clocks compared to vega on 7nm. so what do you need all the extra die space for? it surely does not simply go to waste.
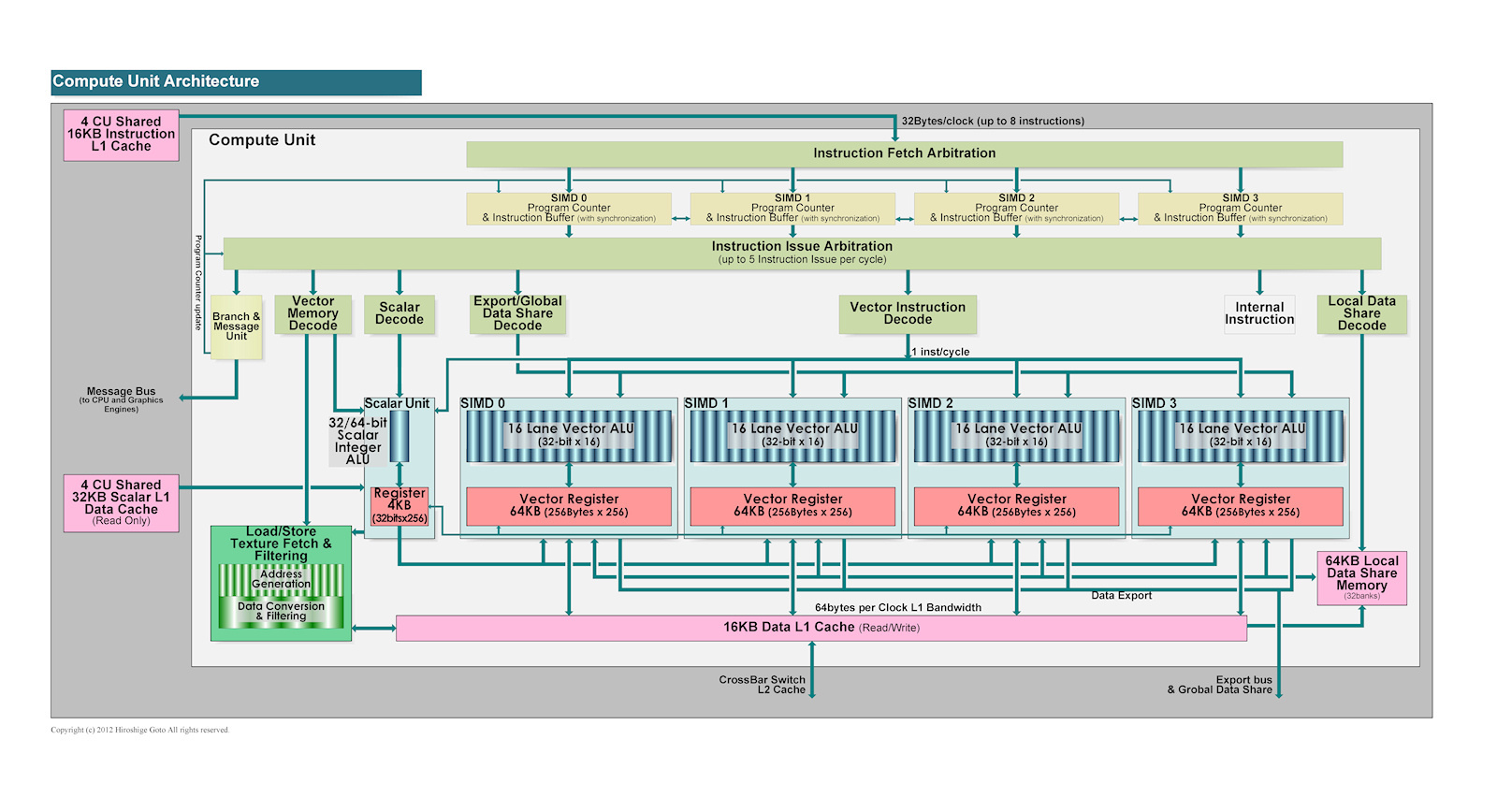
well ok, you could say at this point that vega already had quite a bump in complexety without seeing any significant real world gains. on that topic keep in mind, firstly: vega 10 and 20 have different proportions between frontend components and CU count plainly because it has 64CUs and not around 40. secondly: vega already had a rework of the pipeline which should have enabled a feature called "primitive shaders" that never came to fruition but needed a serious rework of the CUs.
so what then is the kicker behind all this added complexity?
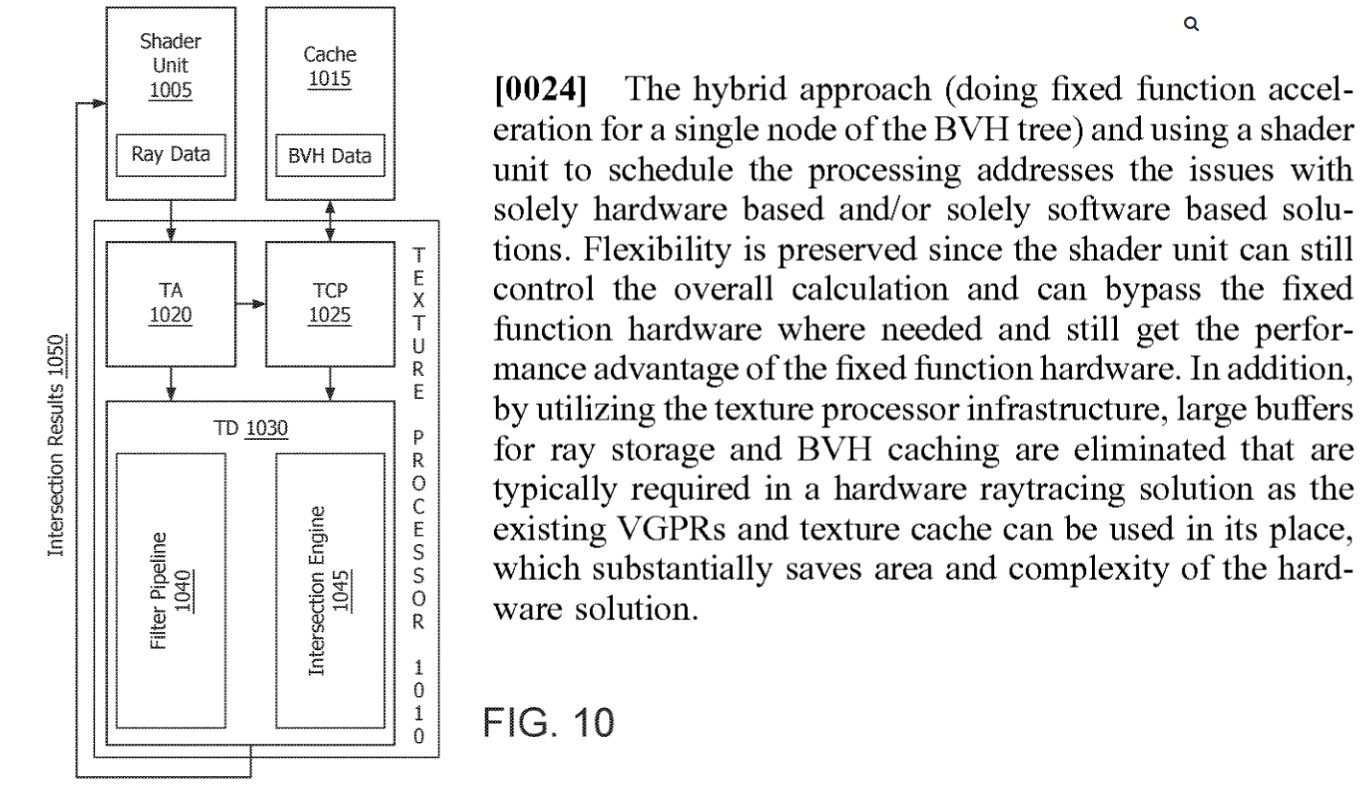
well it might have somehting to do with the fixed function/shader hybrid approach to raytracing, which became public through the AMD patent a few days ago:
https://www.techpowerup.com/256975/amd-patent-shines-raytraced-light-on-post-navi-plans
the authors seem to stress, that this approach is in many ways superior than going with all fixed funcition hardware. especially that it minimizes the die area that lies idle during the other rendering steps compared to fully dedicated hardware.
the ability to use the whole of your available shaders for ray shooting and not rely on just a small part of your die for that step hopefully also alleviates or bypasses the necessity of a denoising step which there is seamingly no dedicated hardware on the Navi die.
to implement that method on die, you would not only need the BVH hardware ("ray intersection engine" as they call it in the patent) but also need to rework the CUs and add paths between components.
so that might mean, that a big chunk of that extra complexity we are seeing might be the bet on what's the next big thing in realtime graphics for the coming decade:
hybrid rendering.

hothardware.com

translate.google.com

")


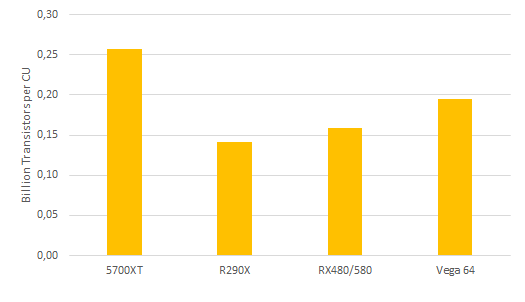





 ]. maybe also the reason why we not seeing big Navi just yet.
]. maybe also the reason why we not seeing big Navi just yet.