ResilientBanana
Member
If this is all true, Microsoft better have Navi, otherwise this will be an upset.
")
Miniature Kaiju said:Oh yeah, just noticed that. I guess that means that each SIMD-VU can be done with a wavefront in 2 cycles rather than 4 cycles. Fewer wavefronts per cycle, but faster, so, lower latency. I guess that's a way of making more efficient use of any speed gains.
dgrdsv said:Wider SIMDs usually mean less efficiency, not more. You're running the same operation on more data but you're also stalling more when there's not enough data for processing. But with next gen going to 4K basis this might be the right move, especially if they'll do something to increase utilization in compute.
Miniature Kaiju said:I imagine that such a move would come accompanied by deeper wavefront queues and smarter scheduling. As you said, 4K and more mixed compute might be enough to keep it fed.
I also imagine that faster cycles, coupled with something like the variable wavefront sizing and a deep, self-feeding queue might do quite a bit to enhance compute RT.

If this is all true, Microsoft better have Navi, otherwise this will be an upset.
Even using cheaper binned HBM3 chips, 24GB worth of HBM3 stacks will provide bandwidth in excess of 1TB/s. They can brute force past any incompatibility plus lower latency to boot!If the game is highly optimised for the original hardware, and if the change to HBM doesn't bring any great improvement in bandwidth, they might end up breaking the original optimisation - leading to frame rate drops etc ..
One possible example I can think of is if the original software is optimised to fetch data in the exact size (and aligned to) the original GDDR6 data width .. the changed to the wider HBM data bus width might result in much reduced utilizations of the wider bus - could even be a disaster for performance .. but I need to think about it more.
Working extreme example - original game uses scattered 32 bit wide aligned data fetches .. when shifting to 128 bit data bus width (HBM) those 32 bit fetches now are ultilising only 25% of the available bandwith.
It's an extreme example.. maybe/maybe not [the old adage - if it can break it will]

Im confused now, wouldn't more SE mean more efficient use of CUs?Indeed being wider (SIMD-32 instead SIMD-16) means less efficiency for normal tasks... it did help the schedule for compute tasks.
Dream on.PS5 having major advantage in loading speed and streaming data will be huge and is a smart engineering decision. It will also makes DF remove the words of "Loading times" " asset pop in" from their dictionary for an entire gen, or unless MS catch up with hardware revision somehow
I hope for the best 14TF!So now we want nothing less than 14TF + HW RT.
and 16GB RAMAnd PC fanboys say we would be lucky to get GTX 1070 performance in PS5

Nah, loading isn't going away yet.PS5 having major advantage in loading speed and streaming data will be huge and is a smart engineering decision. It will also makes DF remove the words of "Loading times" " asset pop in" from their dictionary for an entire gen, or unless MS catch up with hardware revision somehow
I will have to study more... but in theory the increase in SEs decrease the efficiency (AMD said that in their own tests)... they changed the CUs to SIMD-32 that in theory decrease the efficiency too.Im confused now, wouldn't more SE mean more efficient use of CUs?

Gives credance to Sony taking a loss on PS5, exiting times ahead.
Maybe its just for devkits, one of the first pastebin leaks claimed 32GB devkits and 24GB retail.
atm im treating all rumors as speculation not giving more credibility to any one in specific, the pastebin i mentioned is in the OPexcuse the old man's question, but whats pastebin and why should we trust it?
heh.. idk feels super wasteful to use a 512bit bus for a mere 16GBif 512bit really was an option, the old 16GB GDDR6 + 8GB GDDR4 rumor might be true after all.
Is there a full slide deck up somewhere?
excuse the old man's question, but whats pastebin and why should we trust it?
[loves] you .. 
Seems like a huge arch change that nobody is discussing.
Which regions get PS5 first .. or simultaneous worldwide launch etc ..Wth does country rollout in the slide means?
Launch First in NA/EU/Jap etc. before this gen simultaneous ww release wasn't as commonWth does country rollout in the slide means?
4 SE was assumed to be GCN limit and adding more would require a comprehensive redesign that might as well make a new arch. 8 SE is potentially game changer for Navi.Isn't gpu SIMD used mostly for GPGPU?
I have no idea, can't figure it out either.Which regions get PS5 first .. or simultaneous worldwide launch etc ..
Anyone know what the slide "The 99, Not the 1 " is actually mean ?
I think it means they consider collective spending for the retail price of the console and promotionsAnyone know what the slide "The 99, Not the 1 " is actual mean ?
seems like Navi has some magic to it.

Im just theorizing that if they were able to do such a drastic arch change then 1.8GHz gonzolo speeds suddenly dont sound so crazy. Navi is vastly different than Vega.
I will have to study more... but in theory the increase in SEs decrease the efficiency (AMD said that in their own tests)... they changed the CUs to SIMD-32 that in theory decrease the efficiency too.
But you can cover that decrease in efficiency adding more schedulers and fixed functions to each SE (nVidia does that).
Let's see how it will turn out.
It just means focus on the customers you already have, not the ones you don't. This is especially important as the console is nearing it's 100th million consoles sold. The 99 generate more money for the company so they need to focus on them rather than worrying about how they can get the 1 to buy a new PS4.Which regions get PS5 first .. or simultaneous worldwide launch etc ..
Anyone know what the slide "The 99, Not the 1 " is actually mean ?
F FafaladaLordOfChaos any comment on this?
Seems like a huge arch change that nobody is discussing.
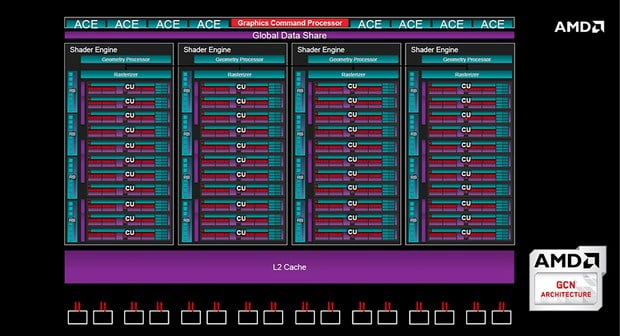

This change really got my attention because it was said to be impossible to add more than 4 SE without a new post GCN arch
Is that related? Seems more like why AMD made GCN like it is.
click pic have fun!
didn't read yet, but komachi posted this after the 8SE Thing...
edit: yeah that's quite old.

I hate feeding into this garbage but, I'll bite.
Third party developer here with contacts at AMD from the old days. Just got our - Pastebin.com
Pastebin.com is the number one paste tool since 2002. Pastebin is a website where you can store text online for a set period of time.pastebin.com
Is that related? Seems more like why AMD made GCN like it is.

Let's track all 4chan and pastebin to check when the official specs are released.Yeah, forget about 4chan or pastebin. It's useless.
Ninja Theory prepares for the arrival of Ray Tracing with Anaconda
At the beginning of the current generation, the current consoles, and especially the original Xbox One model, were accused of not representing a technological break with the previous generation. Maybe that's why this was the first of the generations of modern consoles, to have new models more powerful in the middle of generation. However, it seems that in the face of the new consoles that will arrive in 2020, it does anticipate the arrival of new techniques and more advanced technologies.
One of these techniques that is already emerging as one of the protagonists of the next generation, as they have been in this 1080p or image reconstruction techniques, is the so brought and carried Ray Tracing. A new rendering technique that requires dedicated chips or a great power to achieve it by emulation. It has recently been rumored that one or both models of the next Xbox will be compatible with it, and today we can tell you that Ninja Theory begins to arm itselffor use in its upcoming titles.
Ninja Theory bets on Ray Tracing in real time
As you can see in the website of Ninja Theory, the new job offers published ask for experience in UE4 (something quite normal), Ray Tracing in real time (typical of the new nVidia more powerful), and DirectML a new api graph presented by Microsoft in the GDC this year, incorporated into DirectX and that allows developers to create code compatible with virtually any type of GPU. As you can see Ninja Theory not only prepares for the arrival of Anaconda and Scarlett, but also for a greater focus on the PC.
Surely very soon we will see very similar movements in other members of Xbox Game Studios, but for now it is a very good sign that Ninja Theory is already preparing for the future.
click pic have fun!
didn't read yet, but komachi posted this after the 8SE Thing...
edit: yeah that's quite old.
That is what I thought... this link just shows how the GCN worked until 5.1 and why AMD choose that design over the previous Arch.well it has quite good visualization what a SIMD is and what it does. probably why komachi posted it.
that one is particulary good:
but to be honest. i don't really see what the benefit of two 32 lane instead of four 16 lane SIMDs per CU should be.
the main story is probably the doubling of the front ends.
I love reading stuff like this, unfortunately I'm not a Cerny.
PS5 SSD Leak:
Dev from AAA studio here! Tested a next gen build of our own game and when we try to harness the true power of PS5 the loading times hold up compared to the Spider-Man demo. We don't know how Cerny did it, but there is some magic sauce here.
Yikes are they really doubling down on 8k? Why?

 www.pushsquare.com
www.pushsquare.com
LOL, yeah I wish too. But we both know CELL2 isn't going to happen.So sony is going more innovative and MS is going more brute force 2TF difference possibly. Very interesting if MS is really on vega they might have a ray tracing disadvantage. That troll rumor about PS5 having Cell 2 gave me hope.
So sony is going more innovative and MS is going more brute force 2TF difference possibly. Very interesting if MS is really on vega they might have a ray tracing disadvantage. That troll rumor about PS5 having Cell 2 gave me hope.
So sony is going more innovative and MS is going more brute force 2TF difference possibly. Very interesting if MS is really on vega they might have a ray tracing disadvantage. That troll rumor about PS5 having Cell 2 gave me hope.
Marketing.Yikes are they really doubling down on 8k? Why?
