The problem with the Pentium's 4 pipeline was not the branch predictor, it was the length of the pipeline. It go to the point of being 30+ stages.
So when there was a stall because of a miss with the OoO, the resulting pipeline flush was catastrophic for all operations already in the pipeline.
I know, but that was the point. Even 95% accuracy can not be enough if the cost of a mistake is very dire. Either a hazard when getting to instruction execution or a branch misprediction or a cache miss could wreak havoc (isolated or together).
Now mind you, I'm not saying that a good frontend can nullify cache and memory latencies. I'm saying it can help to hide it.
OoO is technically seen as backend, but the point was that OoO (Issue, Execution but in order retire) with regards to L2 misses is more similar to trying to empty the sea with a bucket. It helps too
")
.
When it works well, a good branch predictor, pre-fetcher and OoO, can do wonders to keep a superscaler CPU with several pipelines, all running at peak performance.
Agreed
.
You might be mistaking what OoO means. It's just Out of Order execution.
I am not confused
. OoO Issue and Execute looks as far ahead in the instruction stream (speculating away when it comes to branches) reordering instructions, analysing dependencies between instructions, resources conflict (limited architectural registers) and detecting hazards that could cause a pipeline flush. It does it… to extract work… to extract available ILP.
The feature in modern CPUs that allow for greater parallelism is superscaler, meaning there are several pipelines in the CPU. Though, of course that each stage has different amounts of units.
Superscalar, ability to have multiple concurrent instructions being processed at any one time came much earlier than OoO.
It is a mechanism that allows parallel work to occur and in a way this means we are extracting ILP, but it is not the only contributing factor. Pentium was superscalar and so was Itanium. In either cases further work to extract ILP was left to the compiler without runtime assistance.
SMT is just an opportunistic feature that tries to fit secondary instructions, in a pipeline that already has different thread on it, but that ha left unused units.
In a way, good frontend and having SMT are counter productive, because a good frontend will leave fewer stages open in the pipeline.
SMT allow, for like 4-5% area cost, to take advantage of the existing mechanism for ILP maximisation to take advantage of multiple threads of execution to keep the instruction units fed as the current mechanisms to do so with a single stream were hitting diminishing returns.
It is to be expected that as technology changes assumptions are tested / challenged. Depending on your design and intended workload SMT may make or may not make sense.
That is why Intel is ditching SMT for it's future CPU architectures. And why Apple already left it behind.
Apple has not implemented it yet, it remains to be seen if they may introduce it later on given how wide their cores are they seem to be prime to do it (they are milking CPU core redesigns quite a lot… both M2 and M3 feel very slowly evolutionary rather than revolutionary designs… GPU cores and NE is where they invested more of their design resources, CPU wise they rebalanced it and added resources [beefing everything up, tons and tons of cache and putting optimised memory very very close to the SoC]).
For a while, many supposed that X86 could only have an 4-wide decode stage. While ARM isa, could have significantly more.
Intel proved everyone wrong, by having a 6-wide decode stage since 12th gen.
AMD is still with a 4-wide decode, but with strong throughput. I wonder what they will do with Zen5 regarding this.
Yes, it is a very interesting area of evolution
.

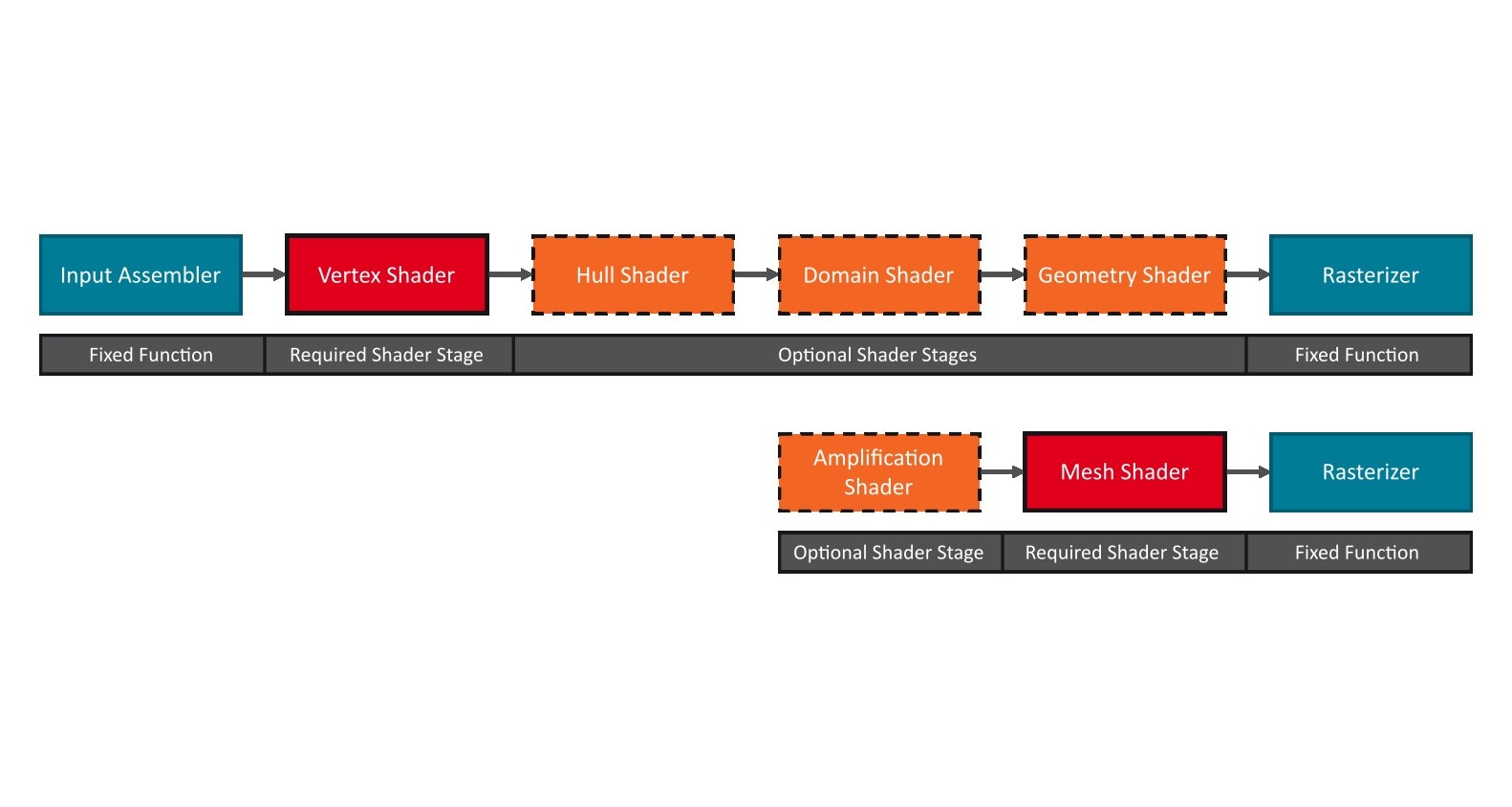
 .
.



 .
.