Since Nvidia's DLSS is a big topic these days (especially in regard to its use in a possible Switch Pro), I was just reading a bit up on it, which led me to an Wikipedia article about AI accelerators. Interestingly, the article mentions the Cell processor as having features significantly overlapping with AI accelerators. Which leads me to my question: would the PS3's Cell processor theoretically have been able to do something similar to DLSS, at least to some extent? Or maybe a hypothetical Cell successor, if Sony had stuck with the architecture after the PS3?
To answer both your questions: Yes, because there's an optimized library for computing GEMMs on SPEs somewhere in Sony HQ collecting dust.
Before I get to GEMMs on SPEs, per Nvidia:
"
GEMMs (General Matrix Multiplications) are a fundamental building block for many operations in neural networks"... "
GEMM is defined as the operation C=αAB+βC, with A and B as matrix inputs, α and β as scalar inputs,
and C as a pre-existing matrix which is overwritten by the output."... "
Following the convention of various linear algebra libraries (such as BLAS), we will say that matrix A is an M x K matrix, meaning that it
has M
rows and K
columns. Similarly, B and C will be assumed to be K x N and M x N
matrices, respectively." --
Nvidia
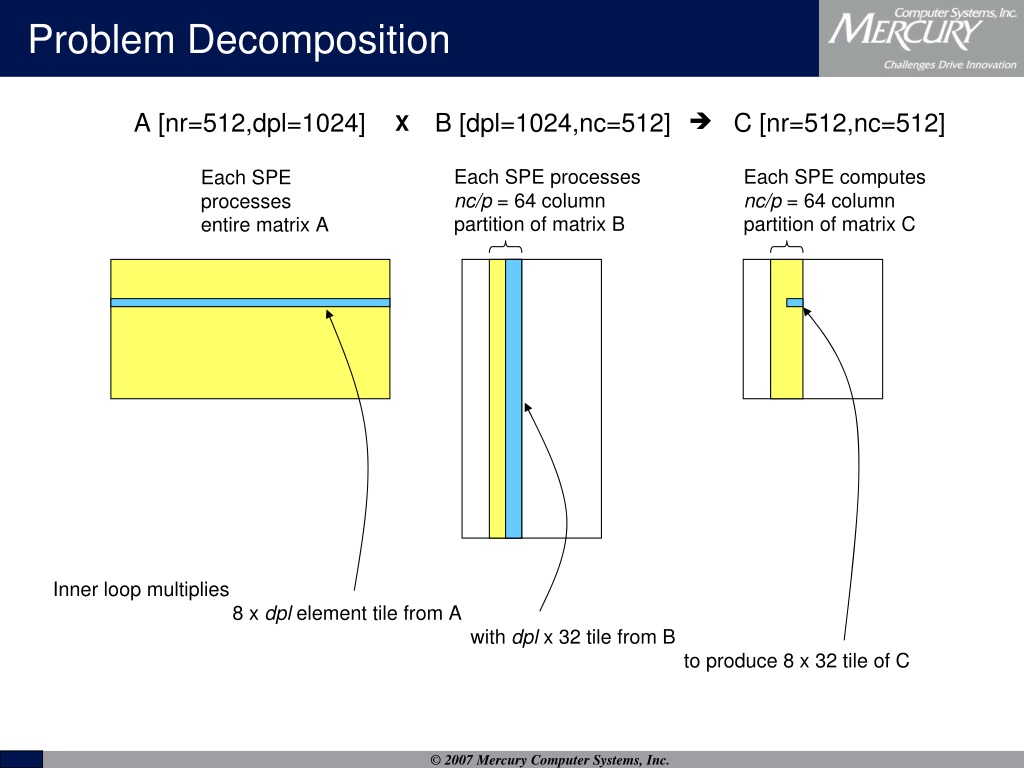
Here are illustrations of what Nvidia described...
To Nvidia's point about following the BLAS convention for GEMMs, the CELL SDK has a BLAS library with
optimized SPE GEMM routines (BLAS Level III SGEMM and DGEMM). These routines put SPEs on the level with Tensor cores in terms of having an optimized procedure for doing matrix multiplication...
A possibly interesting point of fact is that Mercury Computer Systems (once makers of the
CELL-based PowerBlock 200 rugged computer for "applications in network-centric warfare") added SPE GEMM support to its MultiCore library, which the company claimed
"demonstrated superb performance".
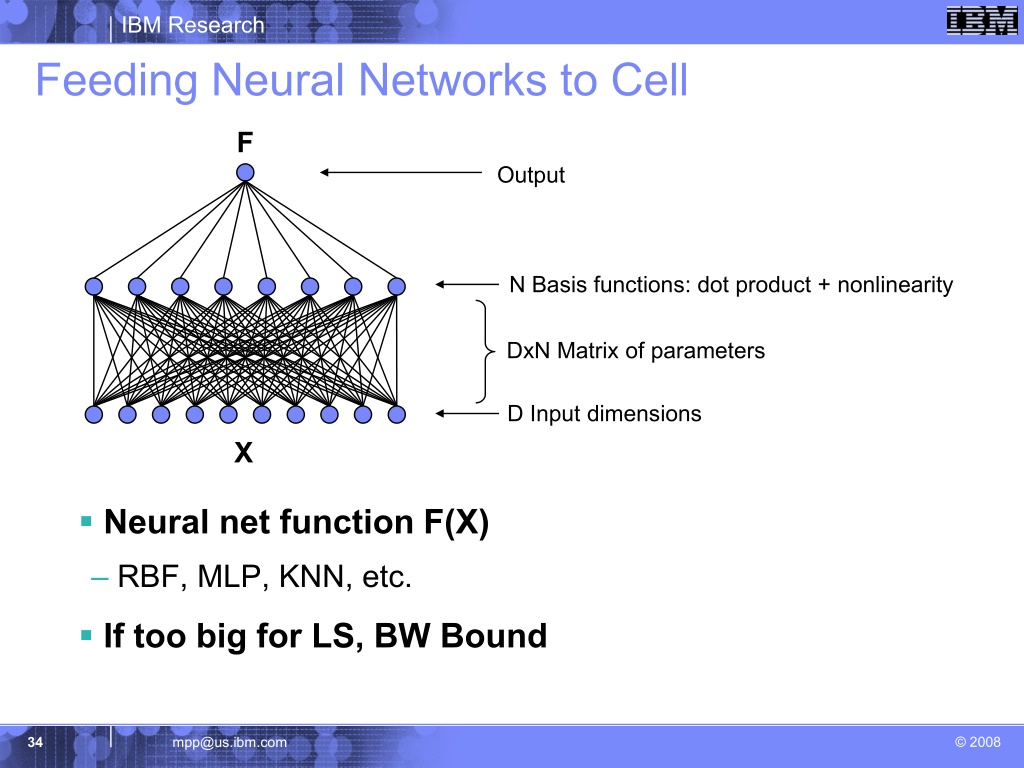
As you may know, training a neural network
can be done with FP32 matrix multiplication or with
a mix of FP16/FP32 matrix multiplication. The existing SPE has support for native FP32 math, but lacks native support for FP16 math (only supports INT8, INT16, FP32, FP64). However, despite this SPEs can still compute FP16 values. For example...
-
DICE's SPU tile-based shader in Battlefield 3 converted the
lighting output of pixels shaded
with FP32 precision into FP16 precision in order
to "Pack" twice the shaded pixels inside SPE local stores
for DMA out to RSX graphics memory (bka 'Rapid Packed Math')
- ex-Ubisofter Sebastian Aaltonen said of PS3:
"Console developers have a lot of FP16 pixel shader experience because of PS3.
Basically all PS3 pixel shader code was running on FP16." --
sebbbi
but the absence of native FP16 math meant
that programmers had to code support for the format from scratch. If a programmer were willing to code in FP16 format/FP16 GEMM support for PS3's CELL, it's highly likely he/she could've built a working SPU-based version of DLSS for it. Had SIE stuck with CELL for PS4,
native FP16 math would've likely been added to the list of "CELL v2" operations at the request of Mike Acton as he was well known to PS4 platform architecture manager, Alex Rosenberg (
timestamped).
Naturally, the existing CELL BLAS GEMM routines would've been updated to reflect the addition of native FP16 support too, as currently it only supports SPE Single GEMM (SGEMM, FP32) and SPE Double GEMM (DGEMM, FP64). With these tweaks to CELL's SPE operations and BLAS GEMM routines, SIE would've had the means to construct a SPU-based version of DLSS for "CELL v2" with few if any compromises in function. How it would've performed is anyone's guess; but there may be clues that hint at it. The 640 Tensor cores of Nvidia's V100
operating on 4 x 4 matrices perform 64 FMAs per cycle for
a total of 40,960 FMA operations in mixed precision (FP16/FP32).
Incredibly (if my comprehension hasn't failed me), a university study revealed that in one example
a single SPE operating on 64 x 64 matrices in FP32 (SGEMM) performed 65,536 FMA operations with 99.8% of its single precision flops (
25.55 GFLOPs out of 25.6 GFLOPs). That's 1.6x the performance of the V100's 640 Tensor cores on matrices 16x larger in size. This counter-intuitive absurd level of performance and efficiency was attributed to "very aggressive" loop unrolling that involved stuffing 4,096 FMA operations into the body of a loop that repeats 16 times.
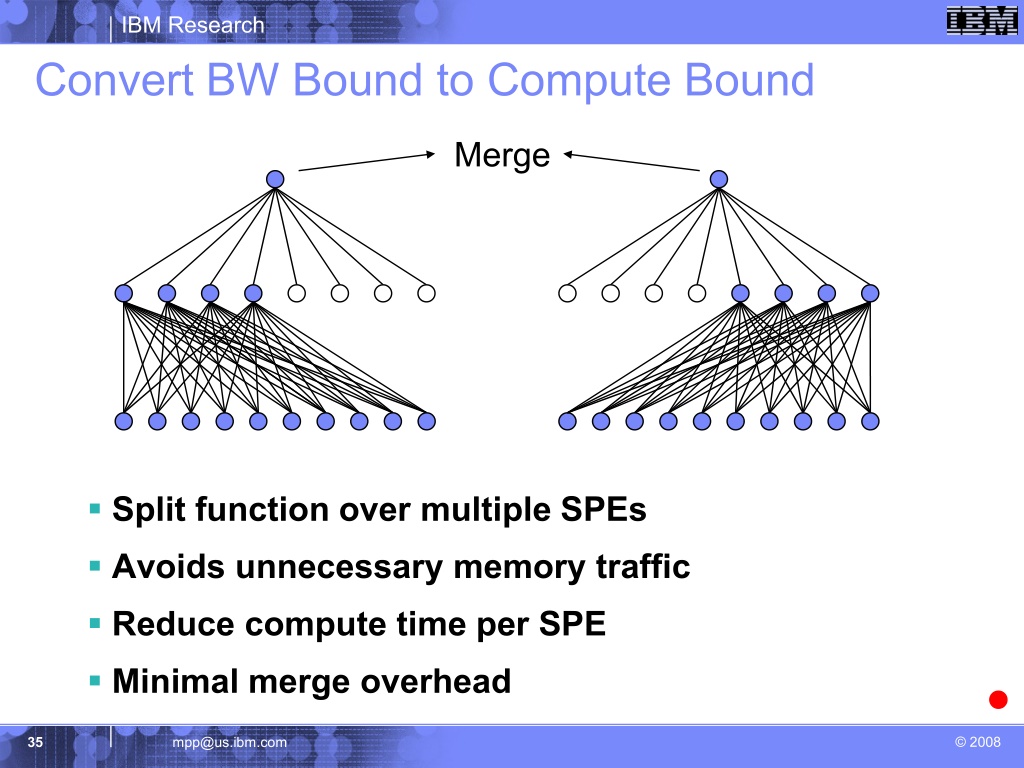
Other reasons for the SPE's high rate of efficiency center around it having
a dataflow design that requires software managed
DMA into/out of its local stores (SRAMs) -- both traits of
IBM's yet to be finalized Digital AI Core accelerator:
"At VLSI, IBM presented a research paper on a programmable accelerator for training neural networks and performing inference using a trained network, with authors from both IBM Research and the IBM Systems group....
The processor is a dataflow-based design, which naturally maps to neural networks."...
"Last, the processor relies on software-managed data (and instruction) movement in explicitly addressed SRAMs, rather than hardware-managed caches.
This approach is similar to the Cell processor and offers superior flexibility and power-efficiency (compared to caches) at the cost of significant programmer and tool chain complexity. While not every machine learning processor will share all these attributes,
it certainly illustrates a different approach from any of the incumbents – and more consistent with the architectures chosen by start-ups such as Graphcore or Wave
that solely focus on machine learning and neural networks." --
real world technologies
Makers of today's high-performance dedicated AI accelerators incorporating foundational aspects of CELL's architectural design (a design that went under-appreciated) into their own designs is a testament to just how forward-looking the chip really was.
What Ken Kutaragi oversaw the creation of was
a scalable general purpose
CPU with SPEs (CPUs) that
rivaled the performance of GPU compute units, all wrapped up in an efficient architecture best suited for the data transfer needs of neural networks. Computing a version of DLSS (and all rest) at satisfactory speed wouldn't have been an issue for a robust CELL successor...












")
